对于地图元素,通常使用经纬度坐标表示,经度为(-180,180], 纬度为(-90, 90]。对于计算确定几个点互相之间的距离时,使用勾股定理足以。
但如果要计算距离某点一定范围内有多少个点时,“遍历所有的点计算出距离再做比对”在性能上肯定无法令人接受。
所以,这种时候,可以考虑直接使用 sql 划分矩形:
1 | select id from positions where x0-r < x < x0+r and y0-r < y < y0+r |
不过,这种查询方式,在高并发场景,性能可能仍然达不到要求
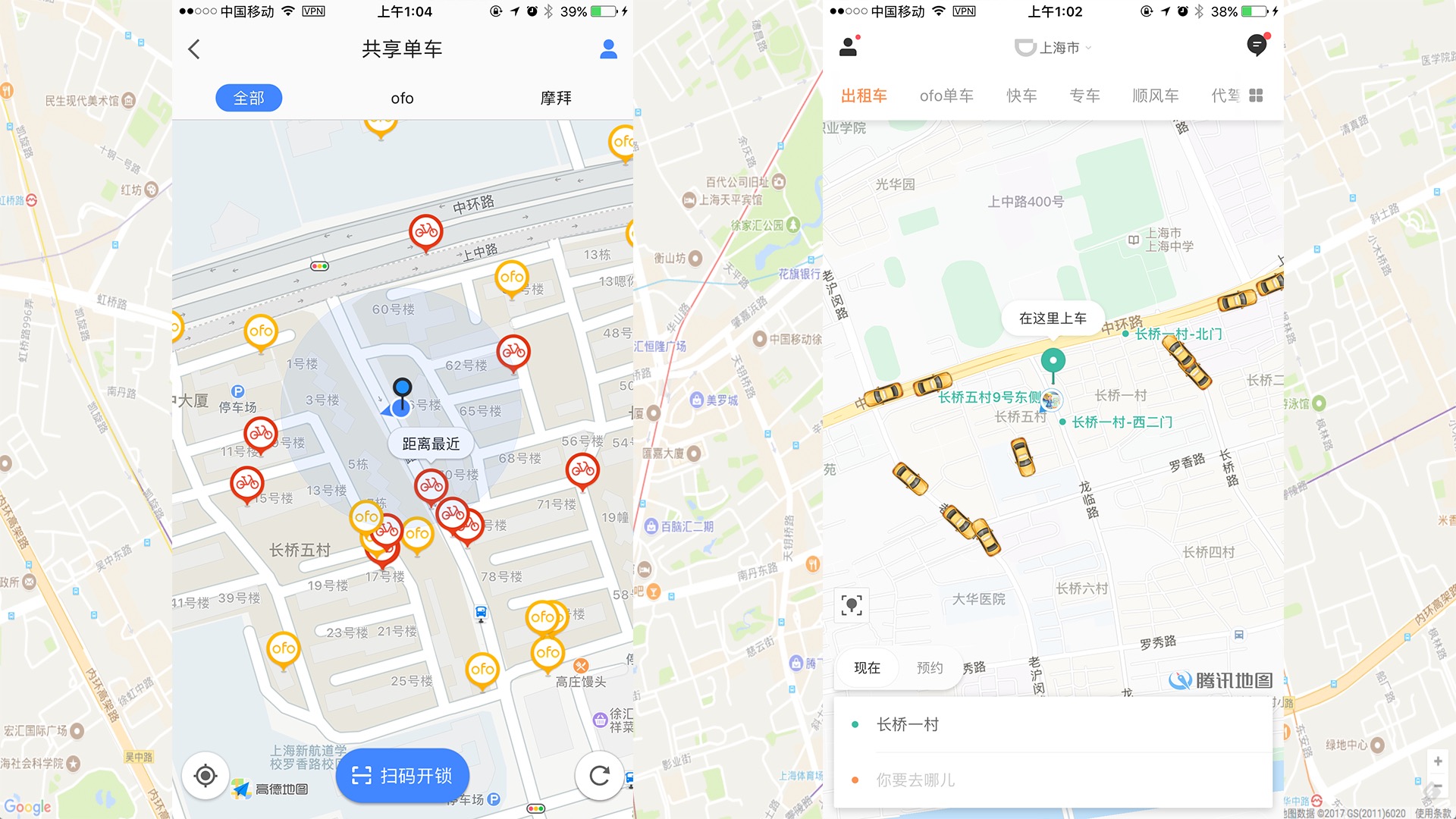
geohash
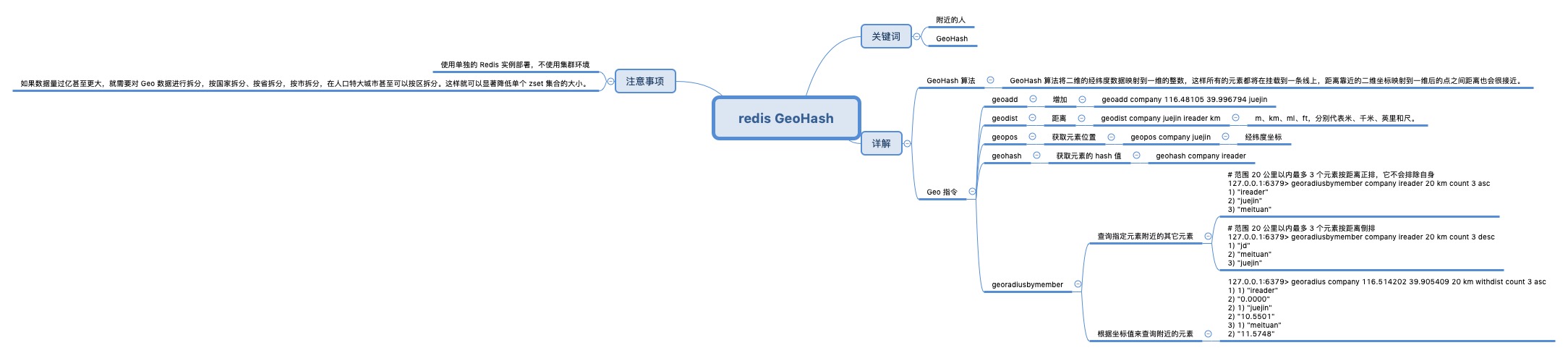
业界比较通用的地理位置距离排序算法是 GeoHash 算法。
以一句话总结的话:GeoHash 算法将二维的经纬度数据映射到一维的整数,这样所有的元素都将在挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。
原理
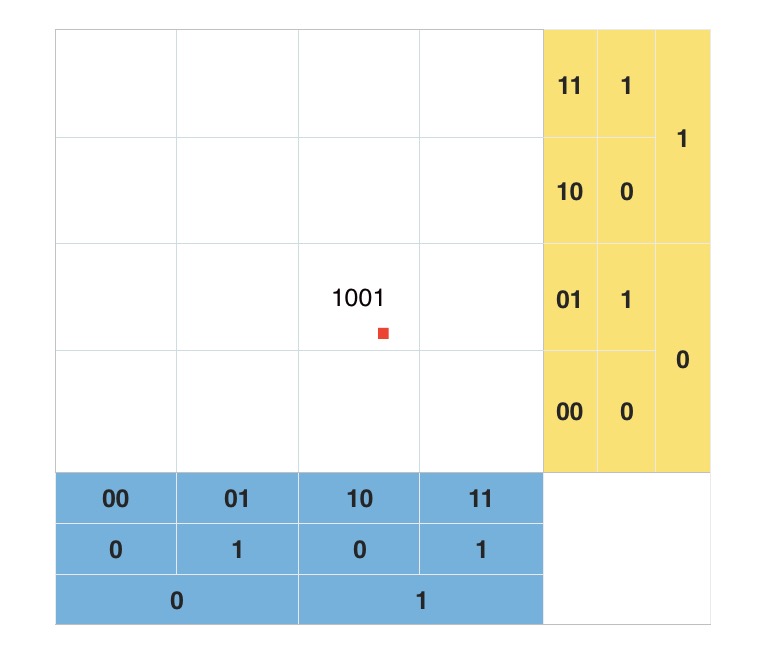
假设有一个点[31.1932993, 121.43960190000007],则:
- 经度在 [-180,0) 范围内的标识为 0,经度范围在 [0, 180) 度的标识为 1;
- 继续划分,经度范围在 [0,90) 的标识为 0,经度范围在 [90,180) 的标识为 1;
- 这样,我们划分 15 次,得到经度的标识二进制串为 110101100101101;
- 对纬度同样划分,得到纬度的标识二进制串为 101011000101110;
- 按照“偶数位放经度,奇数位放纬度”的规则,重新组合经度和纬度的二进制串,11100 11001 00011 00111 10110
- 转换成十进制是 28 25 28 3 7 22,查表编码得到最终结果,wtw37q;
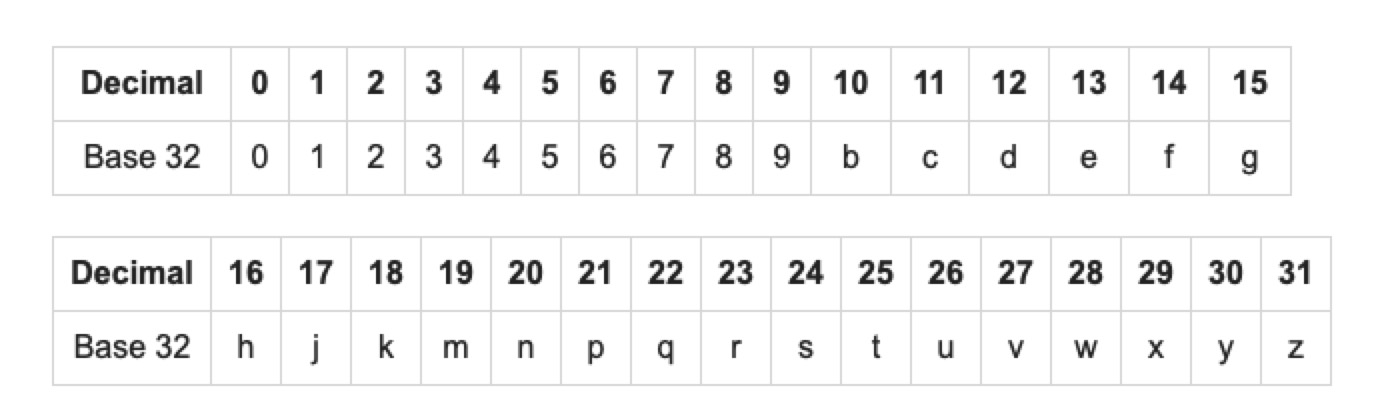

之后,作出查询时,就是:
1 | select id from positions where geoHash like "wtw37%"; |
问题
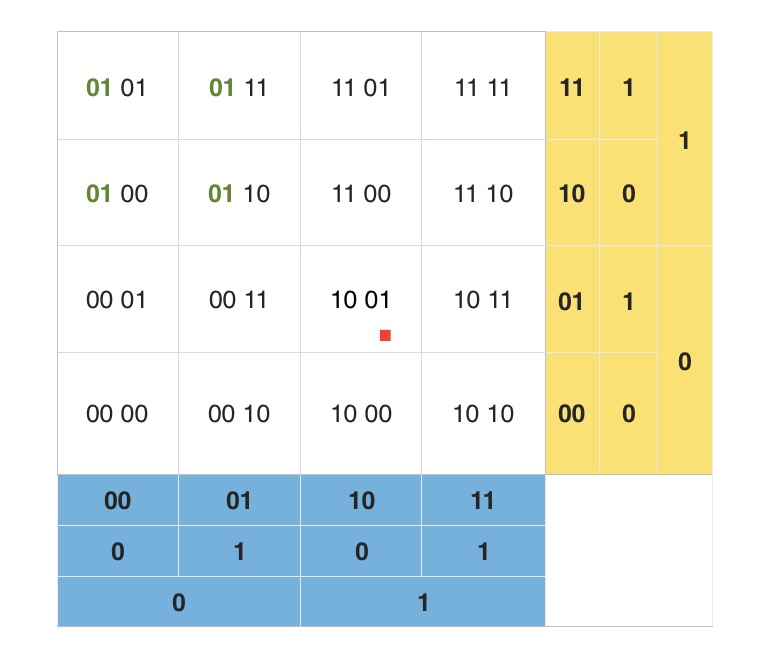
- Z 阶曲线有一个比较严重的问题,虽然有局部保序性,但是它也有突变性。在每个 Z 字母的拐角,都有可能出现顺序的突变。
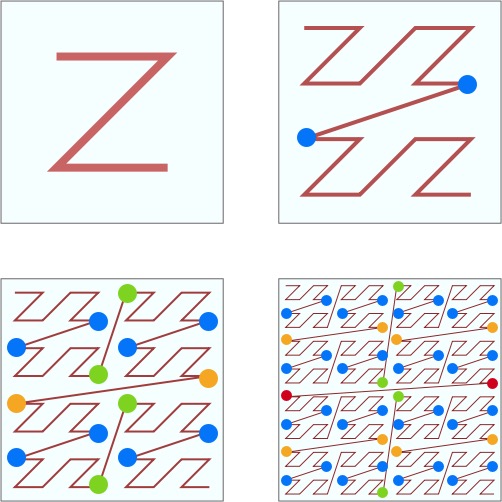 看上图中标注出来的蓝色的点点。每两个点虽然是相邻的,但是距离相隔很远。看右下角的图,两个数值邻近红色的点两者距离几乎达到了整个正方形的边长。两个数值邻近绿色的点也达到了正方形的一半的长度。
看上图中标注出来的蓝色的点点。每两个点虽然是相邻的,但是距离相隔很远。看右下角的图,两个数值邻近红色的点两者距离几乎达到了整个正方形的边长。两个数值邻近绿色的点也达到了正方形的一半的长度。
获取到的点都按勾股定理算一算,排除不合理的点
- Geohash 的另外一个缺点是,如果选择不好合适的网格大小,判断邻近点可能会比较麻烦。
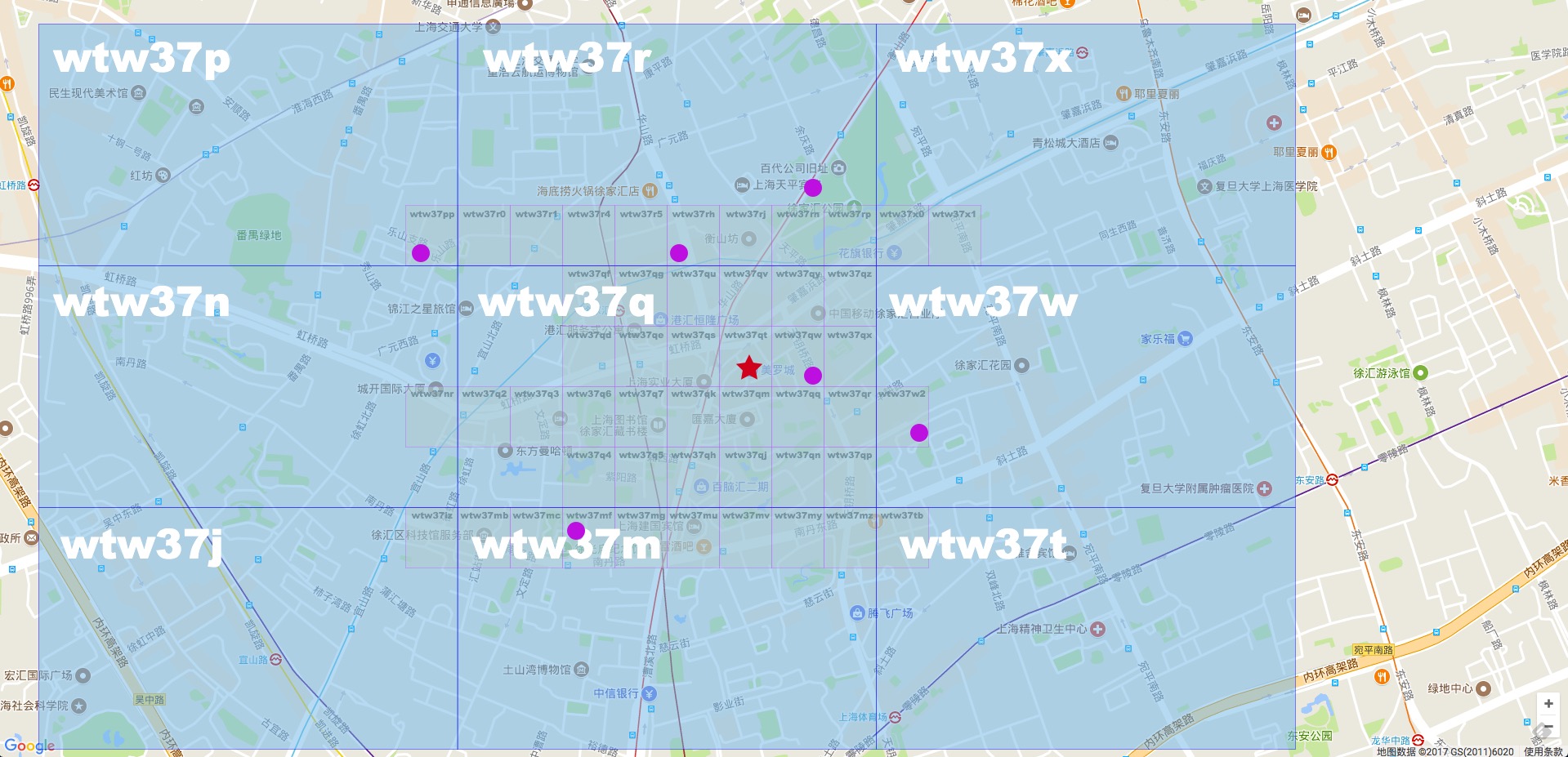
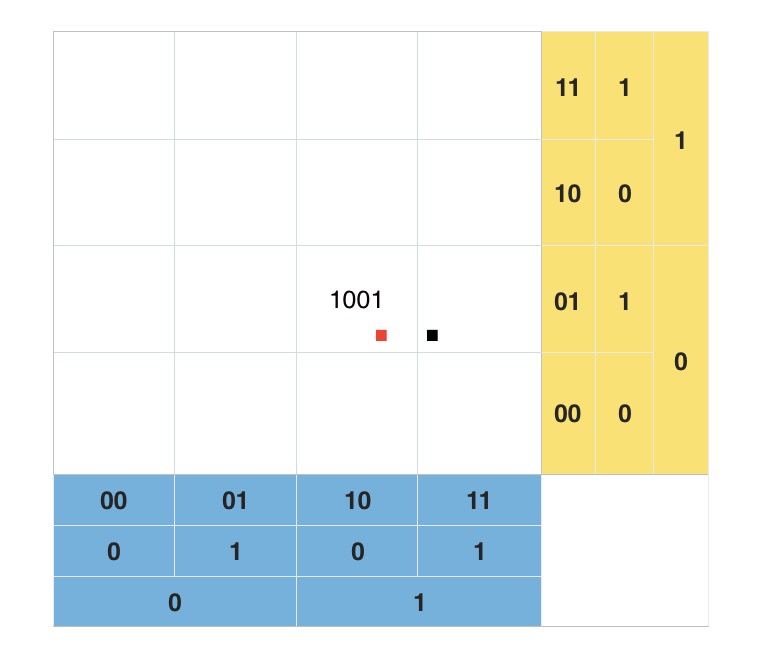
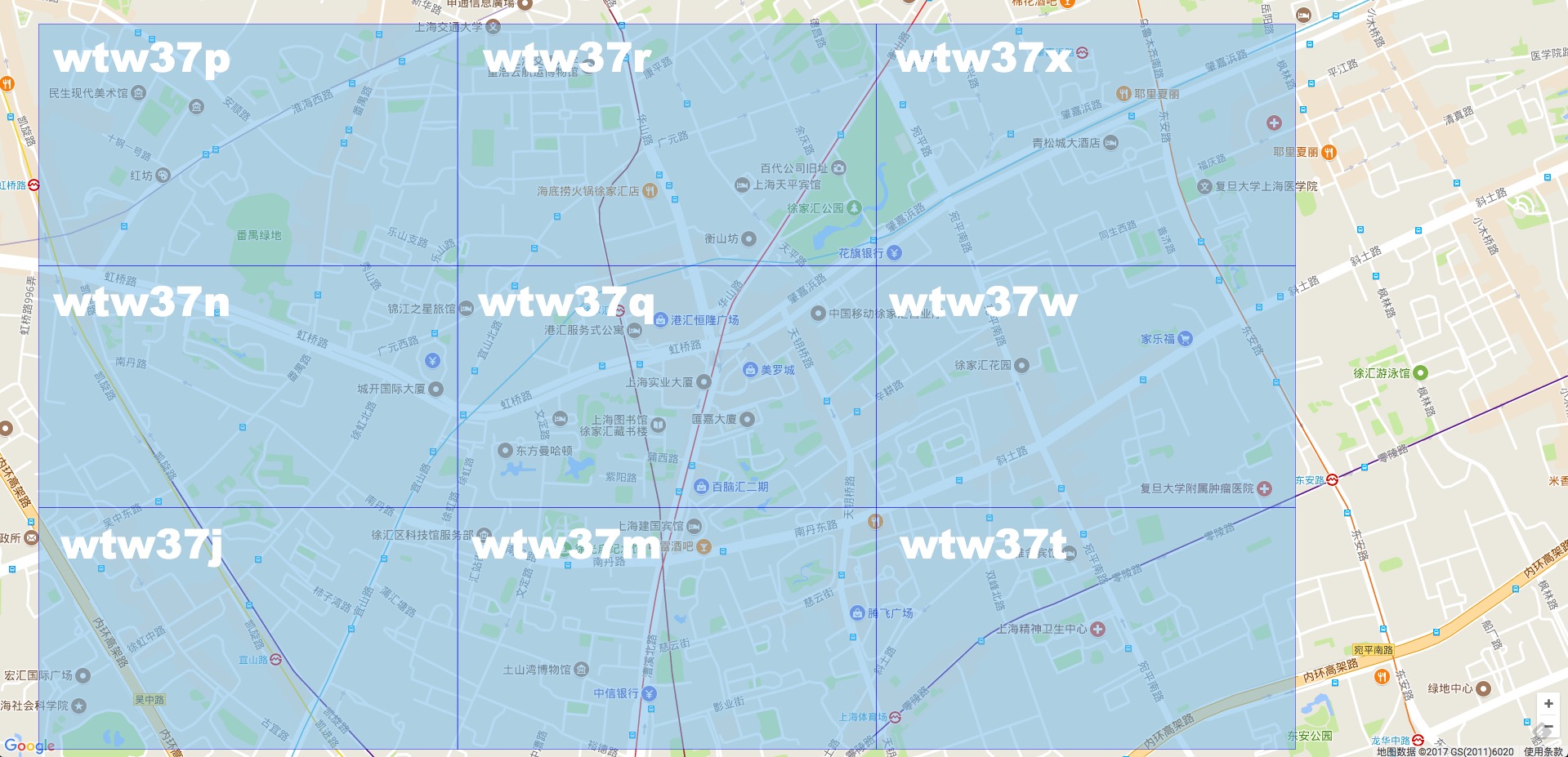
仔细观察相邻方格,我们会发现两个小方格会在 经度或纬度的二进制码上相差 1;我们通过 GeoHash 码反向解析出二进制码后,将其经度或纬度(或两者)的二进制码加一、减一,再次组合为 GeoHash 码。然后获取到的点都按勾股定理算一算,排除不合理的点
使用