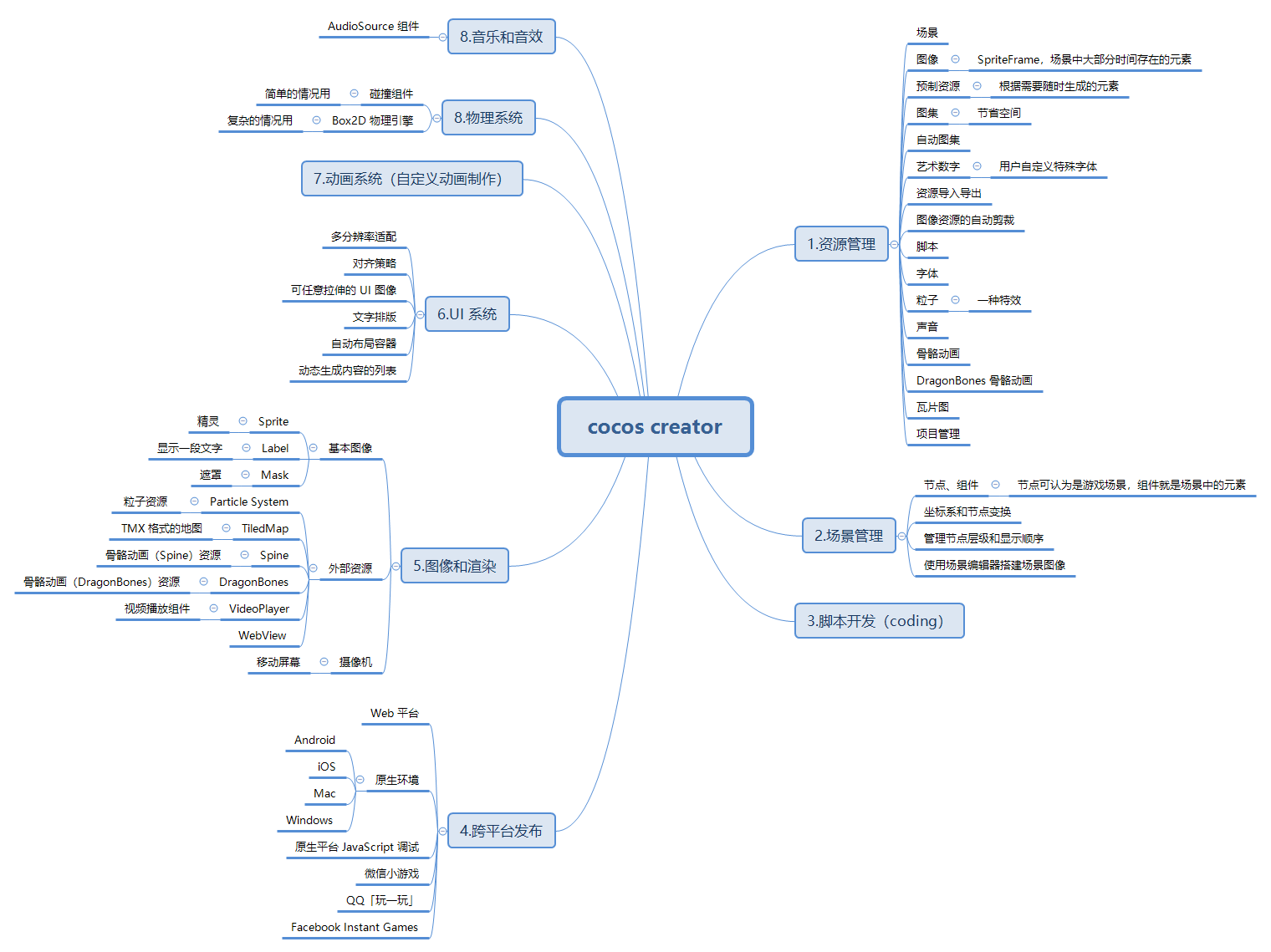
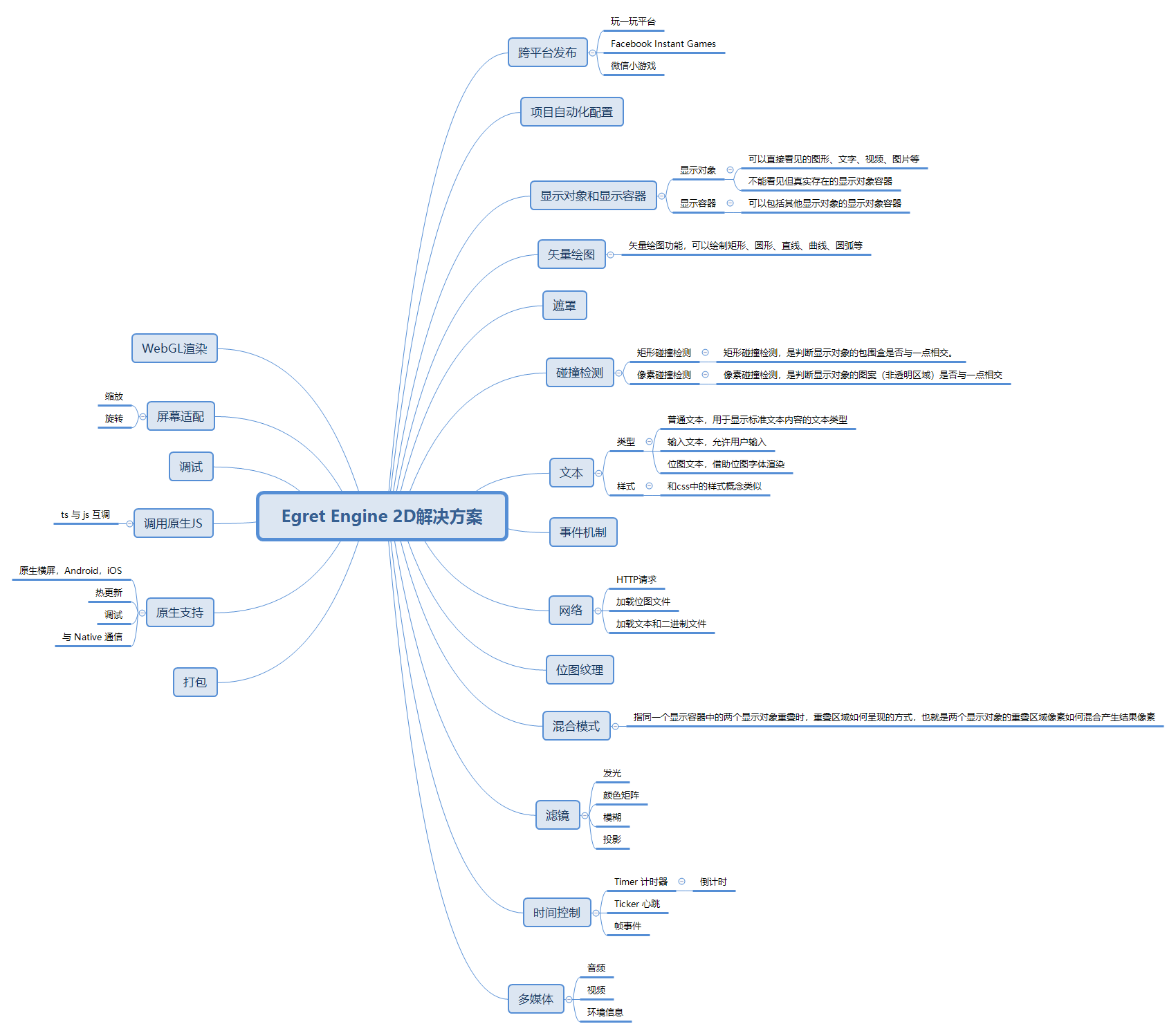
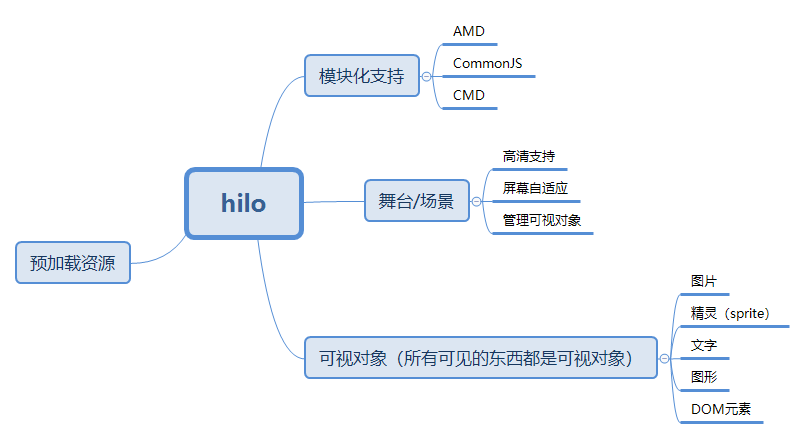
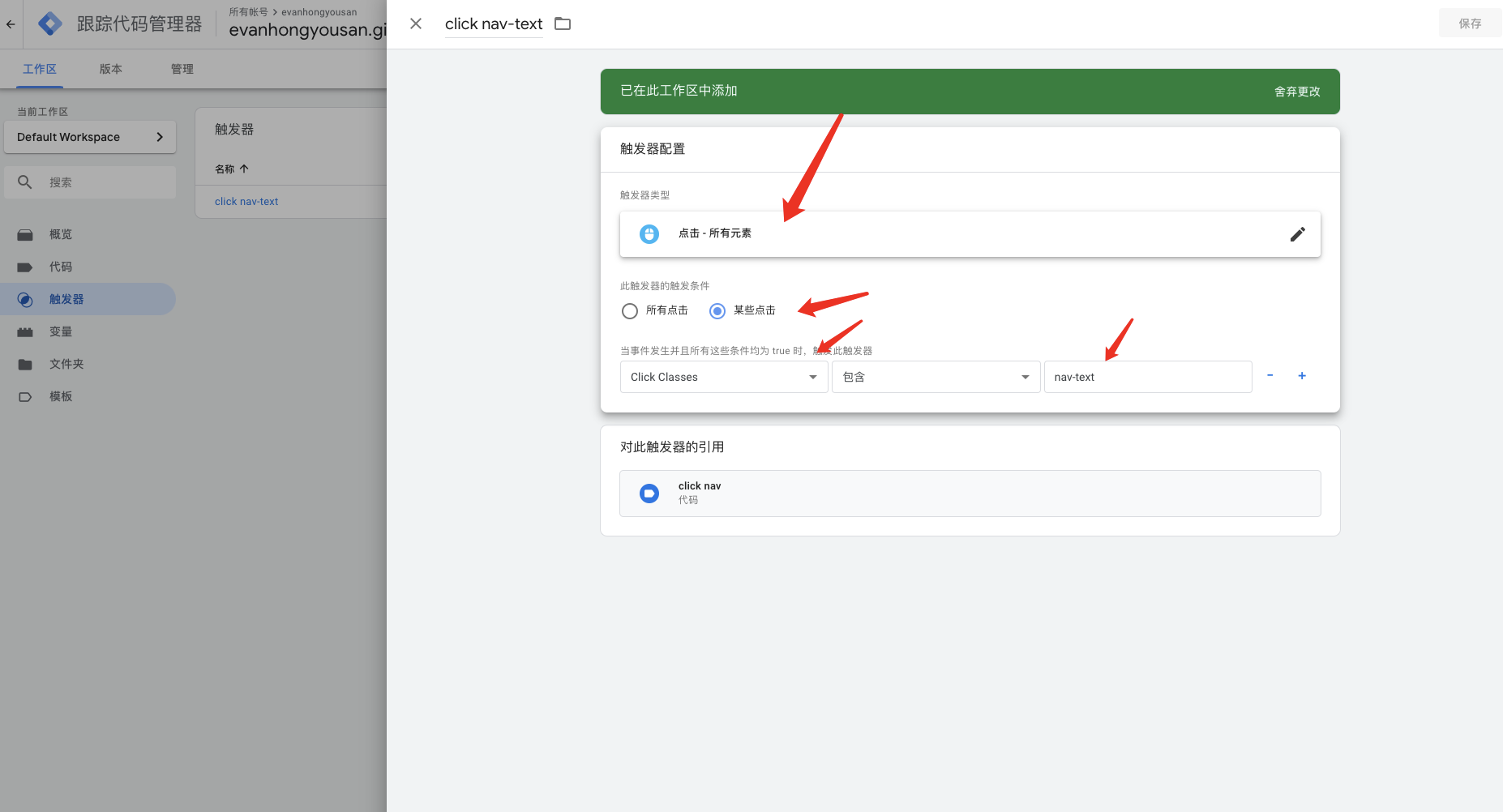
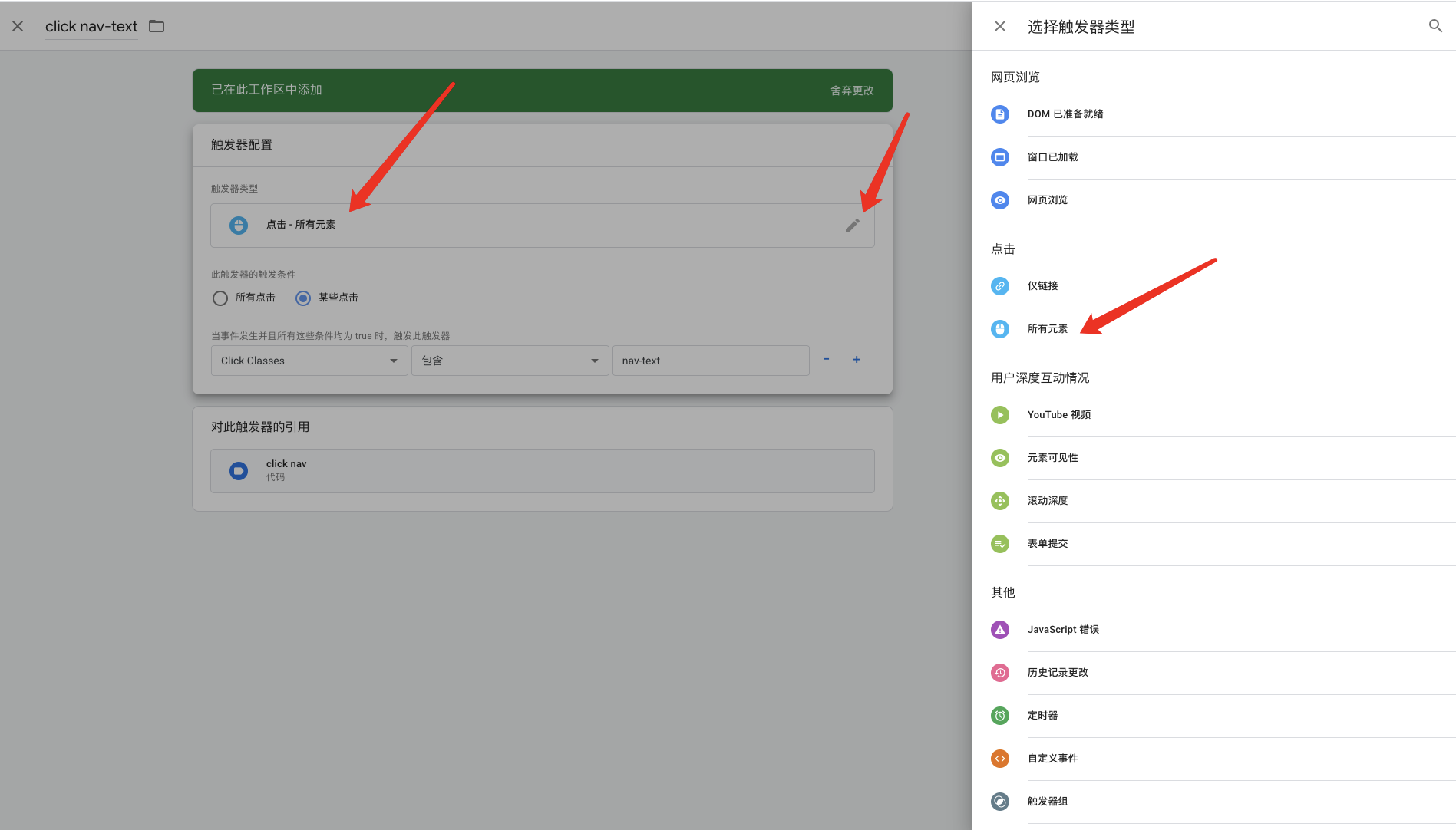
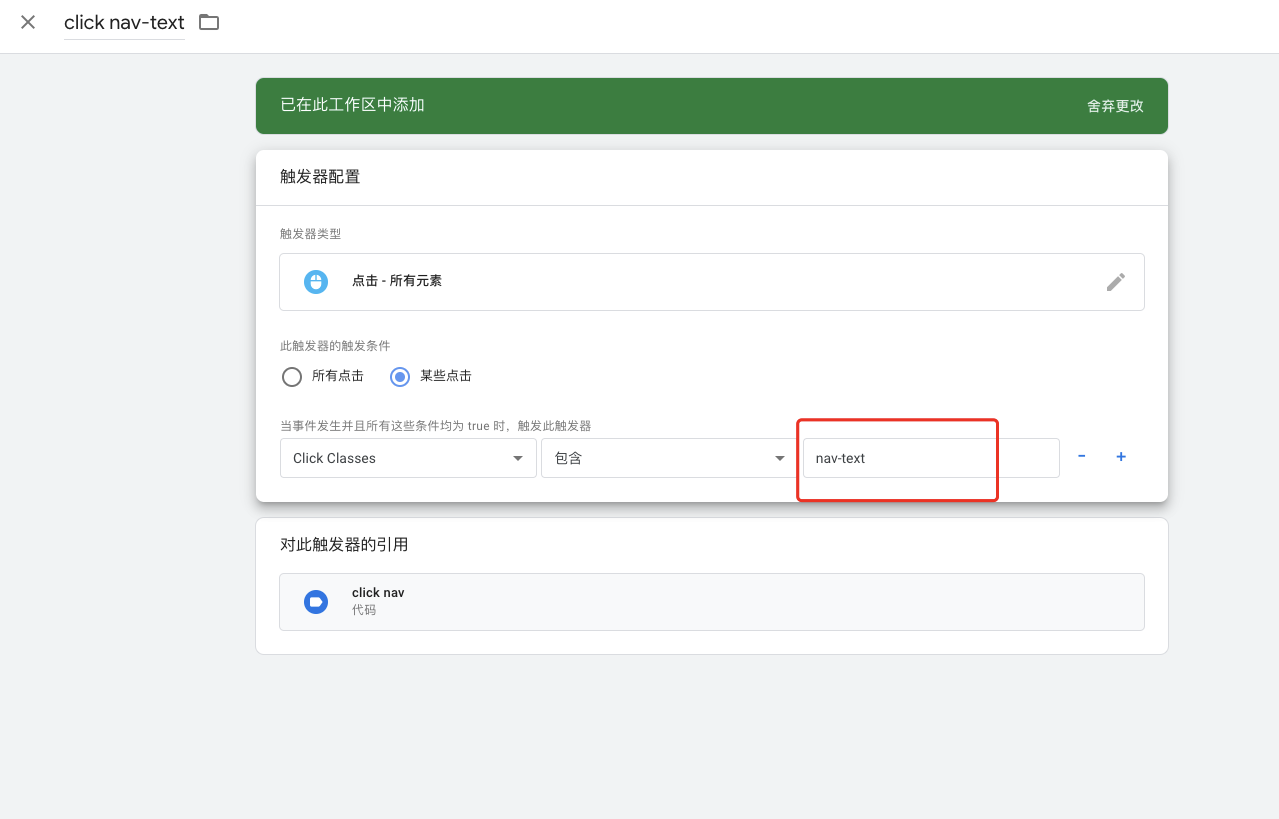
黑客增长法已经是创业公司的新热门词语。忘掉”中枢(pivoting)”和 “迭代”。这些都是增长黑客。这就是问题所在。
听过千百遍的人几乎是烦不胜烦,不知道是什么的人也是一头雾水。
不管你喜不喜欢,黑客增长法正在被不断使用。
而这也是我们每年都能看到几家新的创业公司的原因,其增长率绝对是荒谬的。
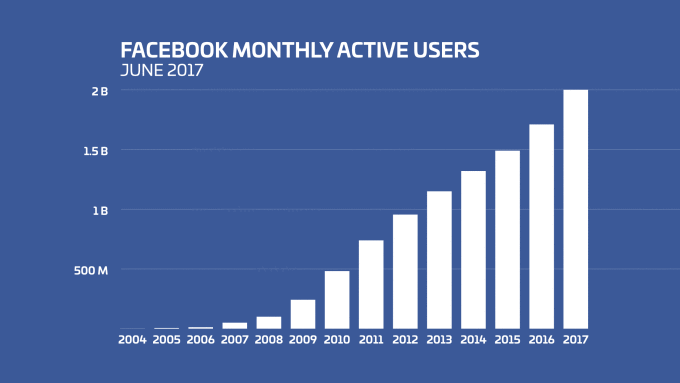
Facebook 就是一个典型的例子。
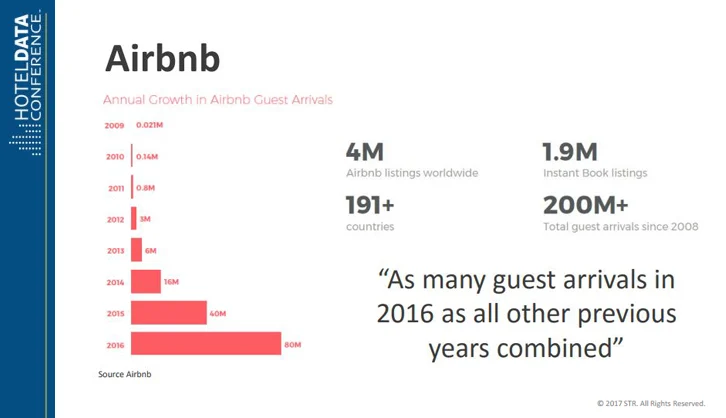
或者,Airbnb 也是另一个例子
黑客增长术才出现了几年,但它已经火了。每个创业公司都在寻找增长黑客。
原因很显然:每个人都想以可怕的速度进行增长,获得数百万用户和美元的收入。
不过,黑客增长术到底意味着什么?
是时候一劳永逸地回答这个问题了。我甚至会在这份增长黑客指南中告诉你如何做。
我将涵盖很多信息,但你可以跳到下面的任何部分。
- 定义
- 概述
- 步骤 1:确保你创造的产品是人们真正想要的。
- 步骤 2:不要针对所有人
- 步骤 3:获取
- 步骤 4:激活
- 步骤 5:保留
- 步骤 6:收入
- 步骤 7:转诊
- 步骤 8:不断改进你的产品
定义
你有可能在线下进行增长黑客行为。例如,你可能会把 20 世纪 50 年代麦当劳在每个州际公路出口出现算作增长黑客行为。
他们意识到州际公路将是大势所趋,所以他们出现在他们知道客户会大量出现的地方。
然而,这个相当新的概念大多适用于初创公司的世界。他们没有庞大的营销预算,所以不能依靠超级碗广告或时代广场广告牌。
这就是为什么他们必须找到更便宜的方式来推销自己。
他们往往拥有的是一种非常可扩展的产品。
比如考虑一下Dropbox。他们的云存储服务提供的基本上只是服务器上的磁盘空间,可以通过互联网访问。
他们可以随时购买或租用更多的服务器,为新用户提供更多的空间。
或者考虑 Uber。这种出租车替代服务依靠普通人用自己的车在 A 地接别人,并把他们安全送到 B 地–而支付则通过应用进行。
2015 年美国有超过 2.6 亿辆注册汽车,这也是非常容易扩展的市场。他们提供应用,无限量的用户可以通过网络下载并使用。其余的由用户提供。
像肥皂这种传统产品,规模化程度不高。每次用完肥皂,你都要买新的肥皂。
但是,每当有另一个用户注册到 Facebook 时,你的体验就会变得更好。
另外,产品的运行方式让它可以推销自己。如果你周五晚上用 Uber 去朋友家,他们问你怎么去的,你就说:”我坐 Uber 去的。”
自然而然,这个词就会传播开来。如果你喜欢这个服务,并且有朋友可以从使用这个服务中受益(除了你从你的朋友在平台上受益之外),你很可能会给朋友分享他。
这就是增长黑客如何大规模地利用口碑来实现我们所看到的指数级增长率。
好了,是时候看看一些用正确方式进行增长黑客术的创业公司的例子了。
但今天,我不会只向你展示伟大的例子。我还会给你一个简单的八步流程,你可以按照这个流程来尝试在自己的业务中应用增长黑客术。
步骤 1:确保你创造出人们真正想要的产品
你会认为这对任何公司来说都是轻而易举的,对吗?
好吧,在以前,你有时可以摆脱一个平庸的产品,如果你只是营销它足够。
例如,可口可乐多年来推出了很多其他软饮料,如雪碧和芬达。 他们中的大多数人都没有可乐的味道好。
(还有,你们谁还记得 New Coke 吗?)

但是,通过广泛(和昂贵)的广告,他们使他们流行,现在他们在杂货店的饮料货架上与可乐本身一起到处都是。
今天要做到这一点要难得多,因为关于一个新产品的消息传播非常迅速。
如果你的产品不好,全世界知道的速度会比你想象的要快。
例如,2009 年,当美国联合航空公司的工人通过互相扔行李的方式传递行李时,他们最终打破了一位顾客的吉他。
他们承认是自己做的,但他们拒绝赔偿这个人的损失。
结果是什么呢?不是一首,而是三首关于蹩脚的美联航服务的歌曲,包括视频都出来了。
第一首至今已经聚集了 1500 万的浏览量。
这是相当糟糕的公关联合。如果你的产品很烂,它可以在比你建立它的时间更短的时间内消失。
解决这个问题的方法是什么?很简单,获取反馈。
你必须以最快的速度把你的产品推出去,开始收集反馈,并定期不断提高产品与市场的契合度。
我从中学到了这个教训。当我们开始 Kissmetrics 的时候,我们用了所有的资金来建立产品。
我们花了一年的时间来打造它。当我们发布它时,我们了解到,我们的客户对他们的社交网络已经提供的指标感到满意。
这可不是什么好事。
你必须采取两个步骤,以确保你的产品击中目标
下面就来看看正确的方法是什么。
- 从提问和回答问题开始,而不是开发一个有很棒的市场契合度产品。
我们在 Crazy Egg 上就是这么做的。人们带着关于客户行为的问题来找我们。
他们说:”我们在广告上花了这么多钱,但实际上我们并不知道客户在做什么,他们在哪里点击,或者他们的行为是什么。”
只有在那时,我们才开始深入研究这个话题,并考虑创造一个能解决这个问题的产品。我们不仅仅是开发一个 “感觉是个好主意 “的产品。
- 一旦你有了想法,就要开始获得反馈。
不要躲在地下室里,开发了半年的东西,然后拿出来。挥舞着它,问:”你们觉得怎么样?”
马上询问反馈。
想象一下,一个朋友在吃饭时告诉你她公司的一个问题。你们一起在餐巾纸上勾画出一个解决方案。
当你拿到那个草图的那一刻,你就可以把它展示给其他人看。
我们只开发了一个月就推送了 Crazy Egg 的第一个版本,开始收集反馈。然后,每个月,我们都会发布一个改进版本。
得益于我们的快速发布和不断收集反馈意见,我们只用了半年时间就有了一个像样的产品,客户也乐于付费。
不仅如此,公开发布更新所产生的媒体和轰动效应,也帮助我们在推出 “疯狂的蛋 “的时候,建立了一个万人的等待名单。
而对于这一万名付费客户,我们的获客成本是多少呢?是零。
另一个绝对搞定反馈部分的公司的例子是 Instagram。
Instagram 的增长一直很疯狂。
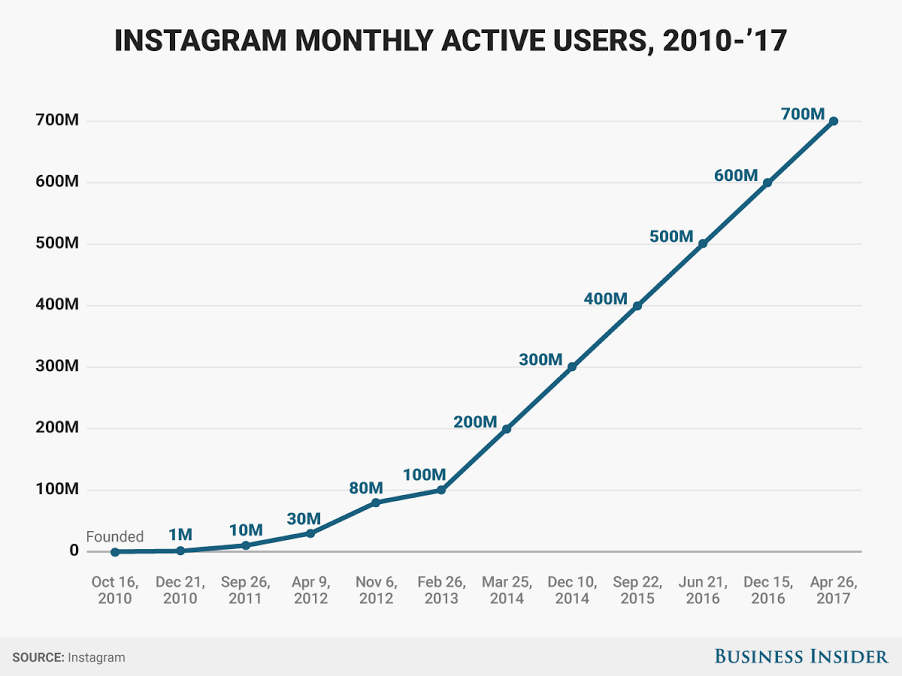
最初,创始人涉足了一款名为 Burbn 的社交网络应用,是为威士忌饮用者准备的。他们意识到,这款应用使用最多的功能是他们的照片分享机制。
随后,他们才开始关注摄影应用,他们认为这已经是一个饱和的市场。
与用户来回交流,他们最终意识到,对于所有的应用来说,分享照片要么太复杂,要么不是应用的主要功能。
他们只是简单地将他们所知道的所有应用中最好的部分,比如 Hipstamatic 的照片过滤器和 Burbn 的分享方式,去掉了所有其他的东西,然后就有了! 他们制作了一个大家都想要的伟大应用。
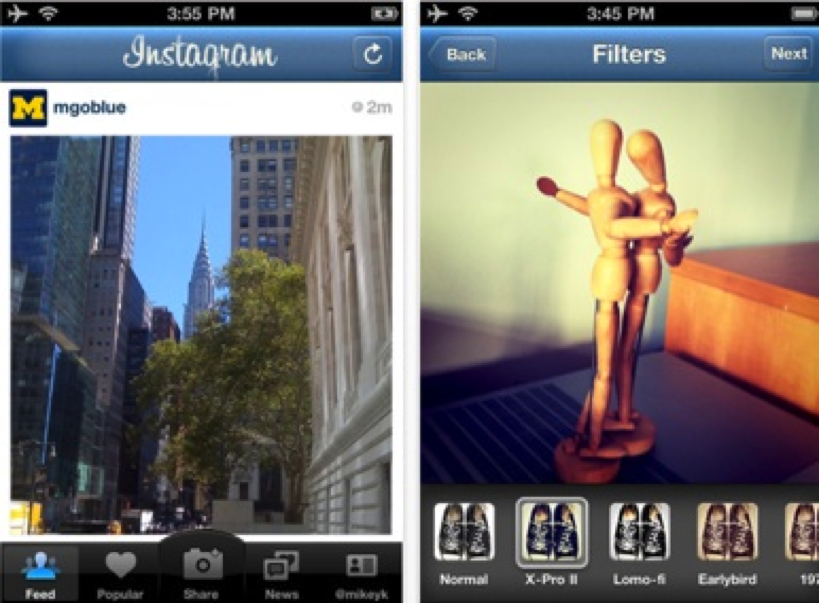
再加上出色的时机(Instagram 与 iPhone 4 同时推出),你就知道他们是如何在第一天就获得 2.5 万个安装量,在两个月内达到 100 万用户。
验证你的想法,确保它不会完全落空。
制作一个伟大的产品的另一部分是验证你的产品理念。
你想知道人们想要你将要创造的东西的一个可靠的方法吗?
请他们为它付费。
如果你想创建一个应用程序,向人们展示城里最好的茶点,而你知道它需要花费 1000 美元来开发,从 50 个朋友那里获得 20 美元(或从 20 个朋友那里获得 50 美元)将为你解决开发成本问题。
而且,你会 100%确定:
- 你的朋友希望你做这个应用(所以潜在的其他人也对它感兴趣)。
- 如果没有成功,你也不会浪费自己的很多钱。
在你还没有产品之前就向你要钱,这似乎有悖常理。
但是,如果你仔细想想,你一直都在为一些事情提前付费:电影票、机票、音乐会、活动、健身房会员卡,以及各种各样的东西。
不管你最后去不去,你都要为这些东西付钱。
验证你的产品就更好了。在某些情况下,如果你最终没有打造出产品,你可以直接把钱还回去。
作家 Ryan Holiday 提前卖出了 2000 多本《障碍就是路》,在他写书的这段时间里,他为自己的燕麦片付了钱,并确保这本书一出版就会成功。
你想知道另一个成功的产品与市场契合度验证的例子吗?看看 Airbnb?
这里有一张关于 Airbnb 历史的伟大信息图。
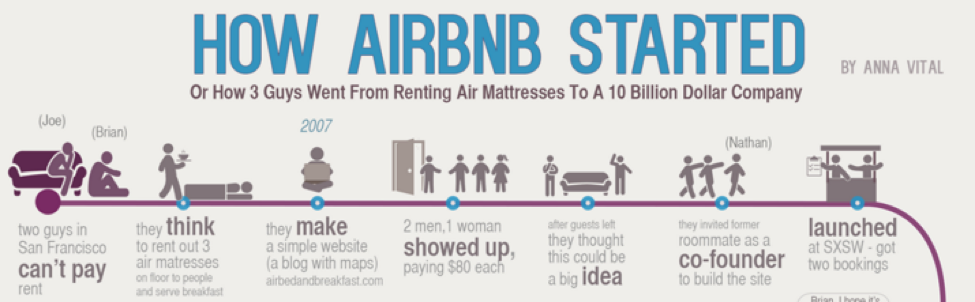
这个想法的诞生是出于需要。创始人 Joe 和 Brian,付不起房租。于是,他们想把公寓地板上的三张气垫租出去赚钱。
当三个人出现时,每个人付给他们 80 美元一晚的费用,他们想,”嗯,这也许值得。”嗯,这可能值得进一步探索”
一旦他们在西南偏南(SXSW)推出,他们就不断接到预订。但他们只得到了几个预订,每周能赚到 200 美元左右。
尽管如此,他们知道兴趣是存在的。他们要做的就是改进产品。
如果你没有想法,就发布免费的内容。
如果你没有想法,就从免费开始。
创建一个博客或 YouTube 频道,并围绕你想建立业务的利基提供内容。在社交媒体上分享你的内容。
这是了解人们喜欢和不喜欢什么以及他们想要和需要什么的最简单方法。这是一个很好的渠道,可以让你的想法得到反馈。
更重要的是,正如你所看到的,如果你收集电子邮件地址,你甚至可以建立一个由渴望和忠诚的追随者组成的观众,他们不能等到你真正推出产品。
你可以通过赠送电子书、开发小测验、或制作电子邮件系列或一组酷炫的视频来实现。现在有了智能手机和 InVideo 等无缝视频编辑解决方案,制作视频比以往任何时候都要容易。
让人们有机会获得你的一些最好的内容,以换取他们的电子邮件地址,你将立即开始建立一个观众。
这是目前最简单的创业方式,而且绝对没有风险。
好的,我们假设你有一个想法,并且你已经验证了它。
接下来,我们将看看你如何避免 Airbnb 犯下的一些错误,使他们的初期增长停滞不前。
步骤 2:不要针对所有人
猜猜 Airbnb 一开始的目标客户是谁?
是每一个旅行的人。
看看他们最初的三位顾客–租他们气垫的人。他们是一个 30 岁的印度男人,一个 35 岁的波士顿女人,还有一个 45 岁的犹他州的四个孩子的父亲。
交叉点在哪里?是什么把这些人联系在一起?他们的共同点是什么?
你看,每个新的创新产品都必须经历一个生命周期。这就是所谓的创新扩散法则,它看起来是这样的。
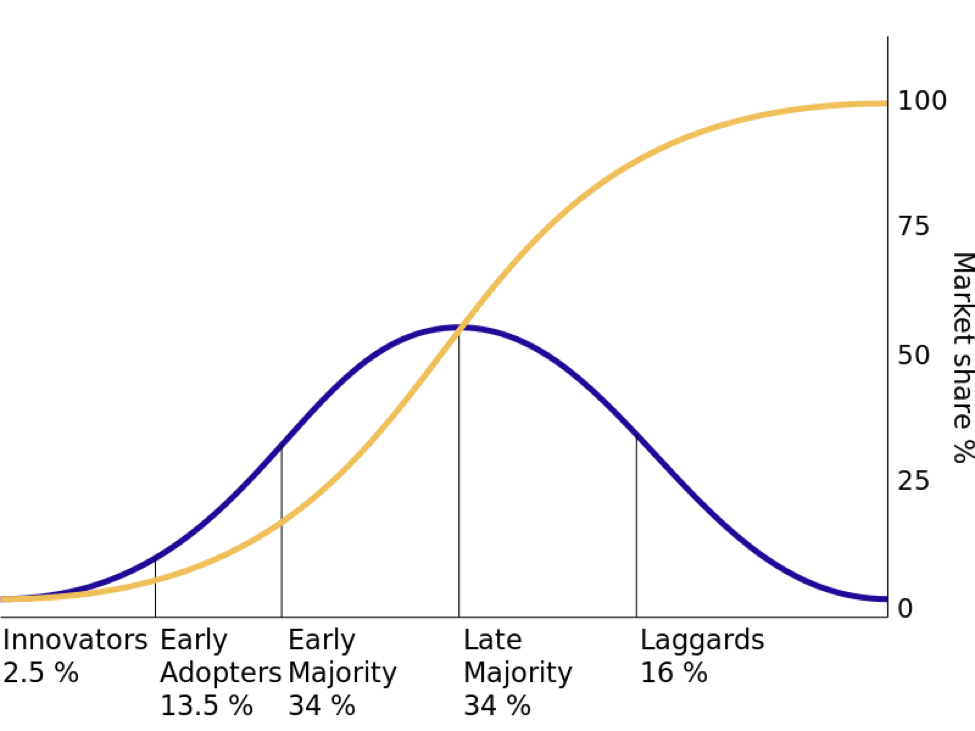
要想接触到大多数人,你的产品必须首先成功通过创新者和早期采用者。
这些都是你需要明确定位的小群体和社区。杰弗里-摩尔写了整整一本书叫《跨越鸿沟》,讲的就是这个现象。
产品要么吸引了前 15%的市场,要么就去死在那里。
如果你的目标客户是 “所有人”,那么你就没有办法在前 15%的市场上实现增长黑客,因为你甚至不知道该说服谁来购买。
而且,你怎么才能做好这个工作呢?
如何锁定少数人,让他们从你的产品中获得最大的利益。
你应该建立一个客户档案。考虑你产品的各个方面。然后问自己。
谁能从我们的产品中获得最大的利益?
要具体。尽可能地描述一个真实的人。
如果 Dropbox 要告诉你他们理想的初始客户,他们可能会说这样的话。
一个 22 岁的白人男性 谁是技术精通, 住在旧金山或湾区, 是瘦,只有几个真正的好朋友, 穿 XYZ 品牌的衣服, 并花了大部分时间在网上。
这就是你应该做的细节。
而且,在一开始,你其实是想专门迎合这些人的需求。
传统的产品,如传统出版商出版的书籍,在推出之前就必须制造大量的轰动效应,以确保推出成功。
对于现代软件产品来说,发布前发生的事情并没有发布后发生的事情那么重要。
Dropbox 并没有举办一场只有邀请人参加的大型发布会。他们只是在 2008 年的 TechCrunch50 上向公众发布。
他们更聪明的举动是在推出服务后,将服务变成了仅限邀请。
这很聪明,是吧?
他们在每年他们的理想客户聚集的活动上推出了这项服务,然后在产品周围营造了一个排他性的光环。
希望加入服务的人需要现有用户的邀请才能加入。由于每个人都想知道 Dropbox 是什么,它是如何工作的,所以等待名单很快就炸开了。
但是,神秘感几乎总是伴随着怀疑。所以,为了让潜在用户了解 Dropbox 是怎么回事,他们制作了一个简短的演示视频。
他们为当时非常流行的社交新闻网络 Digg 的用户定制了该视频。同样,这些用户都是他们的理想目标。网络极客,技术宅,还有书呆子。
创始人之一的德鲁-休斯顿(Drew Houston)在整个演示文稿中放置了大约 12 个内部笑话。在 24 小时内,这段视频就有了 1 万个 diggs(相当于点赞),消息像野火一样传播开来,他们的等待名单上的用户也从 5000 人跃升到了 75000 人。
相比于在谷歌 AdWords 上为一款 99 美元的产品每次收购花费 300 美元,这对他们来说似乎是更好的策略,他们现在拥有 5 亿用户。
这种类型的增长跳跃在初创企业的早期是至关重要的,可以推动产品突破 15%的市场份额边界,而产品要起飞,就需要这样的增长。
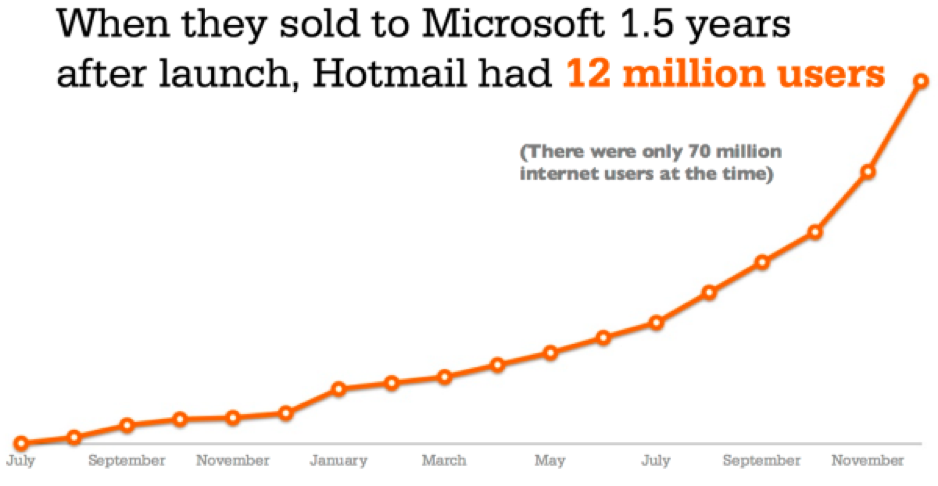
这里还有一个在社区中传播消息的好例子。Hotmail。
如果你是 Gmail 的用户,Hotmail 似乎很老套,你可能早就忘了它。但是,自从微软收购了 Hotmail 之后,他们已经发展到了超过 4 亿用户。在 2012 年左右之前,他们一直领先于 Gmail。
他们做了什么,导致微软一开始就把他们买下来?他们发展得很快。
在辩论广告牌等营销方案时,他们的投资人有了一个想法。为什么不干脆在他们的用户发送的每封电子邮件的末尾放上一张纸条,上面写着 “PS:我爱你。在 Hotmail 获取你的免费邮件”?
这无疑是值得一试的,它将注册人数增加到了每天 3000 人,在 6 个月内,他们的用户群翻了一番–从 50 万增加到 100 万。
之后,增长变得更快。仅仅 5 周后,他们就统计出了 200 万用户。
1200 万用户是相当不错的–尤其是当这意味着互联网上每 5 个人中就有一个人。
通过将 “要求分享 “保留在他们的系统中,他们确保了他们击中了正确的目标群体。
Hotmail 电子邮件用户向他们的朋友发送电子邮件,这些朋友很可能与他们相似,因此也是理想的客户。
Uber 也做了同样的事情。他们等了整整一年,在流行的节日 South by Southwest(SXSW)上向时髦人士和科技人士免费发放乘车券,推广他们的服务,而不是依靠广告。
但所有这些成功的故事都带来了一个重要的问题。
你如何才能发现一个等待发生的汹涌的成功?一个出色的想法和一个糟糕的想法之间有什么区别?
在这一点上,我们转向盗版指标。
PayPal 黑手党是一群企业家和投资人,他们都是通过 PayPal 一炮而红,然后在硅谷创立了其他公司。
Dave McClure 曾是 PayPal 的市场总监,他之后也创办了一些公司。但最引人注目的是科技孵化器/加速器 500 Startups。
而 Dave 也明白增长黑客思维和品牌营销理念之间的关键区别。
大约十年前,Dave 发表了他对创业公司指标的看法。他的观点是衡量几个关键的增长驱动因素,而忽略其他一切。
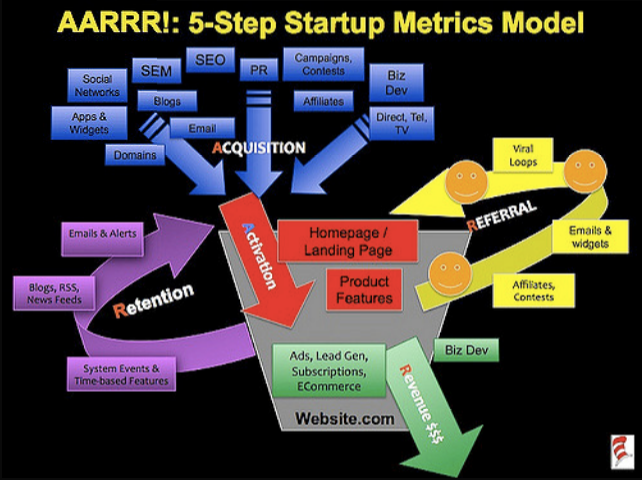
他用有用的缩写 AARRR 概述了漏斗阶段的指标。用户于是亲切地给它起了个绰号 “海盗度量”。
所概述的漏斗阶段包括:
- 获取: 你如何让人们知道你的名字。
- Activation(激活):如何让人们知道你的名字。如何给用户一个快乐的第一次体验。
- 留住用户。你如何让他们回头看更多。
- 收益:如何让他们赚钱。如何让他们赚钱
- 推荐:如何让他们告诉其他人。你如何让他们告诉其他人。
你可以为每个阶段挑选出几个关键指标,准确地了解你的努力(和想法)的回报情况。

然后,根据这些知识,你知道创业想法是否有吸引力,或者你是否应该转向其他东西。
漏斗顶端的第一个阶段是收购。
这措施正是它的声音。你可以看看新的网站或应用程序的流量,甚至可以看看新的眼球来估计你的影响力。
你有多少人暴露在你的信息传递中?在这里,你要看的是付费广告、公关、SEO 等方面的表现。
只要确保不惜一切代价避免虚荣的指标。
例如,如果你在 Facebook 广告上花了钱,但所有这些访客都立即跳转,那一开始就是不合格的流量。这意味着,你可能找错了目标人群。
这说明你需要再去充实这些客户角色。
所以你可以在你的获取指标中增加层次,比如所有网站访客至少点击了两个页面或者至少停留了十秒钟。这告诉你这些人确实对你的产品感兴趣。
第二步是看激活度,也就是在访问你的网站或应用后停留的人数。
戴夫-麦克卢尔将其称为 “快乐的第一次访问”。
有时,这意味着一个硬性目标,如选择进入或注册。但除此之外,它也可以适用于高质量的访问,即有人在你的应用里面使用了一个关键功能,或者在网站页面上浏览的时间超过了几分钟。
这也是我当初创建 Crazy Egg 的原因。
Google Analytics 可能会告诉你,有 100 人访问了你的主页。如果你在分析像 SEO 这样的获取策略,这很有帮助。
但如果你想弄清楚这 100 人在你的网站上做了什么,那就没有帮助了。
你根本不知道他们是否觉得这个页面有帮助,是否很好地提供了他们正在寻找的信息,或者他们是否有潜在的兴趣注册。
而这些东西最终决定了他们是否成为付费客户。
这就是 Crazy Egg 发挥作用的地方。
你可以根据他们的行为和点击量,从字面上看出他们是否在激活。
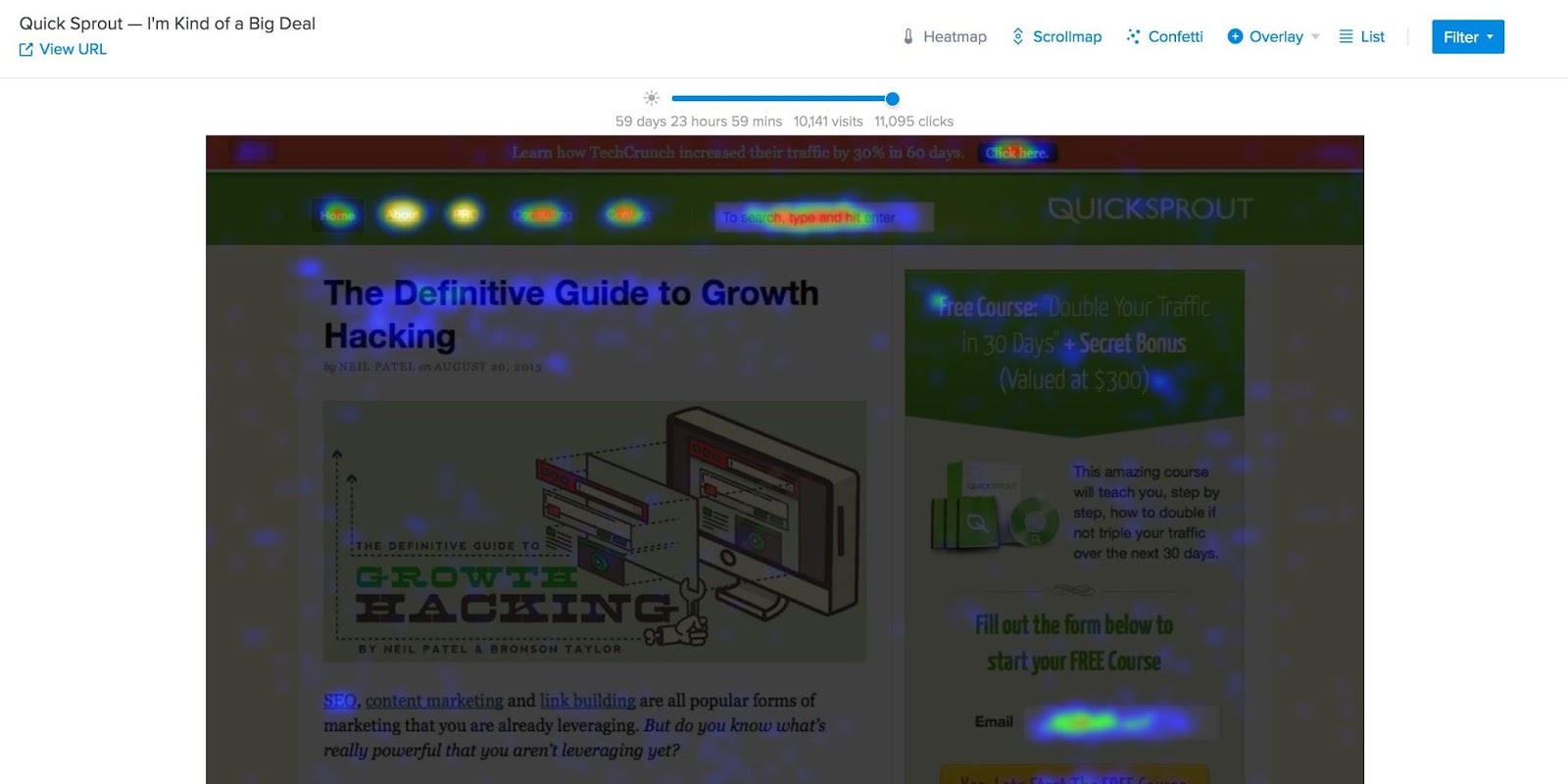
让人们到你的网站很容易与广告。获得合格的人是一个有点困难。
但实际上如何让这些人选择在或注册?这完全是另一回事。
它告诉你,人们是否真正喜欢你的产品概念。
在获得这些激活,或快乐的第一次访问后,下一步是长期保留他们。
想一想移动应用吧。
你很兴奋,急于下载那个大家都在谈论的新应用。你前往应用商店,点击下载,几乎无法控制自己的兴奋。
你用了几个小时,很开心,但后来又出现了一些事情。于是你把它收了起来。
而且你再也没有登录过!
你并不孤单。说真的,每个人都会这样做。
今天我们用手机的时间比用台式电脑的时间还多。84%的时间我们都在用手机,我们都在手机应用里。
然而应用的平均留存率却很糟糕。看看这张可怕的图,让应用主们看看。
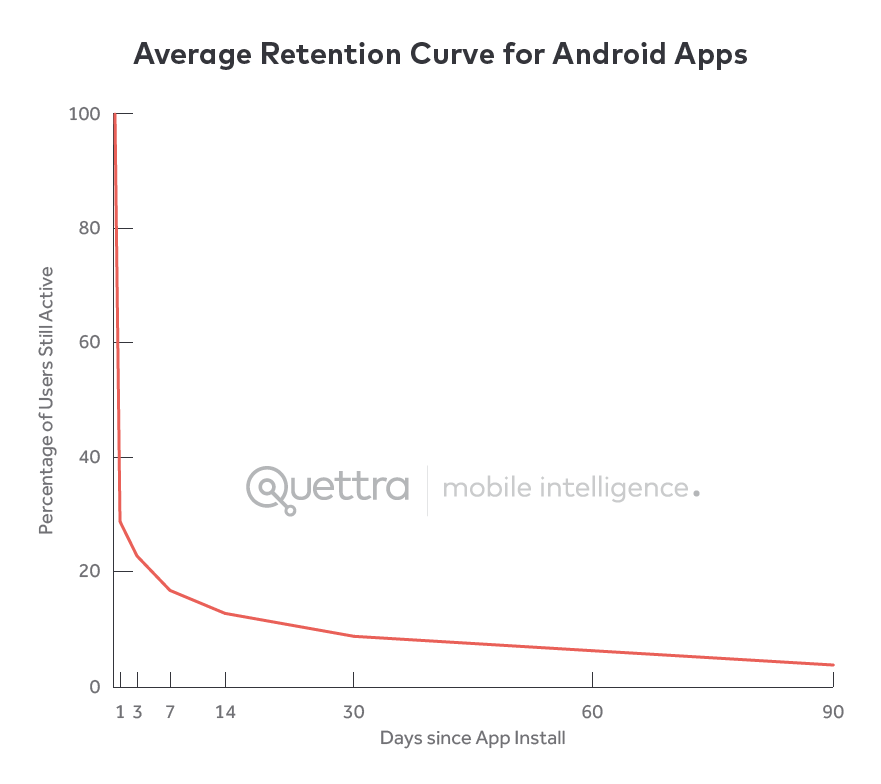
这就告诉你,几乎 80%的用户在下载后三天内就会离开,再也不会回来。这个数字在几个月内会变得更糟糕,上升到高达 95%。
这就是为什么留存如此重要。你在广告上花钱,或者创造一个很棒的首次体验,但流失会杀死大多数创业公司。
你失去客户的速度会比你获得客户的速度更快,你很快就会失去现金(和业务)。
《哈佛商业评论》和贝恩公司发表的一项旧研究表明,大多数新客户在一段时间内都无利可图。
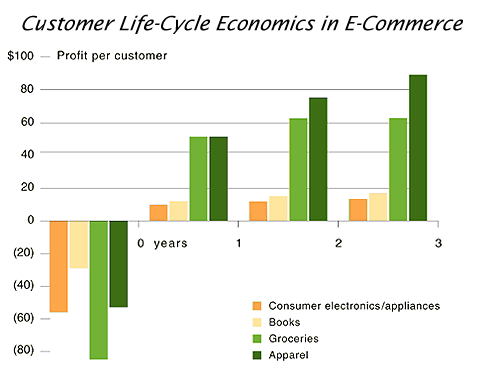
我们今天可以争论实际的数字,但同样的基本原则仍然适用。许多新客户在一开始是无利可图的,因为你必须在广告、人员、办公场所等方面花钱。
更糟糕的是,大多数 SaaS 公司每月只收取其价值的一小部分。这意味着你需要将一个客户保留 3 到 6 个月(甚至可能是 1 年),才能重获新生。
大多数营销博客文章都集中在获取渠道或战术上。他们谈论 “钱在列表中 “如何让电子邮件订阅者购买他们的第一个产品。
他们是对的……在一定程度上。
但真正的增长黑客知道,钱在客户名单中。你通常可以通过专注于增加客户保留而不是专注于新的收购来更快、更容易地增加收入。
因此,除非你是在移动应用业务中,否则人们在第一次或第二次参与后退出是一个糟糕的坏迹象。
没有多少公司能像 Dropbox 或 Facebook 那样建立病毒式的推荐循环。事实是,这需要一些特殊的事情同时发生。
你需要时机,一个惊人的产品,以及网络效应。当一个人对产品的使用增加了另一个人的价值时,就会发生这种情况。
这就像 1+1=3 一样。
但无论哪种方式,你仍然希望尽可能多地推动推荐。同样,这些是快乐的付费客户向他们的家人、朋友和同事推荐你。
再说一次,如果你做得好,这应该是很容易赚钱的。
为你传播消息的客户越多,你在收购上的花费就越少,这意味着你离盈利越近。
你的客户应该告诉他们的朋友,并催生你的产品。Net Promoter Score 是我最喜欢的衡量技术之一,因为它非常简单。
但你要继续阅读下面的内容,才能知道如何正确使用它。
到目前为止,我们所做的一切都只有一个目标。收入。
最终,人们给你冷硬的现金是最好的产品验证形式。
要达到这个目标可能需要一段时间。可能要经过几次反复或枢纽才能打出一个成功的组合。
但是,如果你把前四个步骤都做好了,收入的问题就会迎刃而解。
现在你明白了做增长黑客决策的框架。你看到了每一个都在帮助你定义成功方面扮演着不同的角色。
接下来,让我们开始深入研究。
我们将通过历史上一些增长最快的公司所使用的具体策略、技巧和黑客来深入探讨其中的每一项。
我们将从漏斗顶端的收购开始。
步骤 3:获取
肖恩-埃利斯可能创造了增长黑客的概念。
但 Eric Ries 帮助将其普及到大众中。
在 Eric 出版《精益创业》一书之前,科技界和软件界是人们知道许多核心增长黑客理念的唯一地方。
埃里克帮助把它放在了地图上,把它正式化,使它可以适用于世界各地各种规模的公司和各个行业。
那本书中最重要的主题之一是关于增长的三大引擎。
这是公司扩大获客规模最可靠的三条路径。但同时做多于其中之一的事情几乎是不可能的。
诀窍是要弄清楚哪种最适合自己的产品类型:
- 病毒式 - 想想 Dropbox。你的成长主要是通过其他人将你推荐给他们的朋友、家人或同事。
- 粘性–想想 “疯狂的蛋”。你创造了一种无法抗拒的体验,让人们尽可能长时间地停留在你的身边(从而向你支付越来越多的费用)。
- 付费型–想想 Groupon。你花了 50 美元来获取一个客户,而这个客户最终将为你的企业带来 500 美元的价值。
这三个 “引擎 “中的每一个都能发挥作用。然而,每一个执行的程度主要取决于你的业务。
现在让我们分别去看看每个引擎如何以及何时发挥最大的作用。
- 去病毒化–是时候拿出大招了。不过,去病毒化与针对所有人是不同的。
这一步只是意味着挖掘更大的系统和更大的用户群,并利用同行产品的影响力,真正渗透到大部分市场。
你的目标客户仍然是你的理想客户,但你正在扩展到所有人都存在的平台。
Dropbox 用病毒式推荐策略杀出了一条血路。
给人们提供免费的存储空间,让他们向朋友推荐产品,简直是天才,因为它做了两件事:
- 它激励 Dropbox 用户更频繁地与他们的服务共享文档
- 它让更多的人认识了这个品牌,让从来没有听说过的人免费获得一点样品。
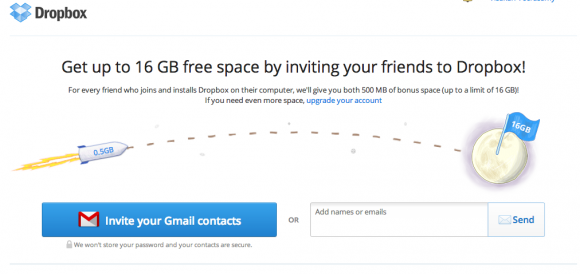
当这种推荐朋友的策略开始产生效益时,他们将其发挥到了极致。
这是与 Dropbox 的另一个关键区别。
许多公司过于分散投资。他们在这里投入 100 美元,在那里再投入 100 美元,看到的是 1%的微薄投资回报。
所有的初创公司都是现金紧缺的。这甚至是那些筹集了大量资金的公司。
原因是你经常要和庞大的企业集团竞争,他们的资金是你的几十亿,而你的资金是几百万。
小公司就不能分散投资了。他们需要把所有的鸡蛋放在一个篮子里,以产生尽可能大的回报。
如果有些东西不奏效,你就尽快改变方向,尝试其他东西。
Dropbox 循环使用了几个不同的想法,直到他们找到了病毒式推荐朋友的方法。当他们看到它的效果时,他们加倍努力,给用户提供更多的空间。
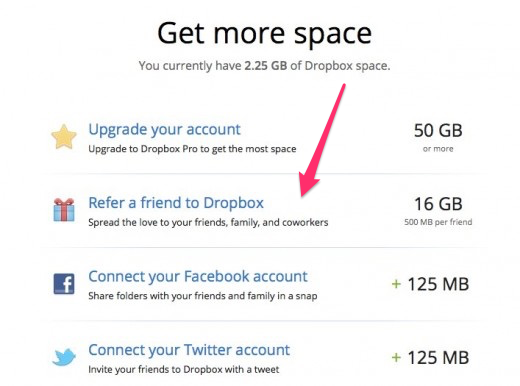
这听起来很像应该在漏斗中更进一步的 Referral 指标。而且在一定程度上是这样的。
但不要搞错了,这是他们领先的收购增长杠杆,因为订阅量增加了 60%。这是他们领先的收购增长杠杆 因为订阅量增加了 60%。
添加其他操作,比如连接你的社交账户以获得更多的存储空间,就像是火上浇油。
然而,他们花了一段时间才想明白,这种策略会如此有效。
例如,在打这个战术之前,他们尝试了广告活动和公关的付费策略。
据创始人德鲁-休斯顿(Drew Houston)说,没有一个成功。于是他们不断迭代,直到找到了行之有效的策略。
为每个用户提供激励措施,让更多的人加入到平台上,是启动病毒式营销活动的好方法,但让你的产品自己来营销就更好了。
苹果公司就是这样做的,他们的广告很好地运用了这一策略。还记得流行的 iPod 广告,黑色的剪影和白色的耳机吗?
2004-2008 年,这些广告随处可见。

通过将耳机做成白色,苹果确保每个人都能认出他们。耳机通常是黑色的,所以通过调整这个功能,他们把所有的客户变成了行走的广告。
你还想知道另一个例子吗?
WordPress 正在为 29%的在线网站提供动力,而且它是免费的。不过,免费版有一个问题。
您的域名将始终显示为 wordpress.yourdomain.com。
每个访问您的免费 WordPress 博客的人都会立即知道这是一个 WordPress 网站。
但是,让我们来谈谈一个更强大的增长黑客。
在 Facebook 将其彻底接管之前,MySpace 统治了这个场景。他们是最大的平台之一。
事实上,他们是如此之大,以至于 YouTube 利用他们的成功来飙升流量。
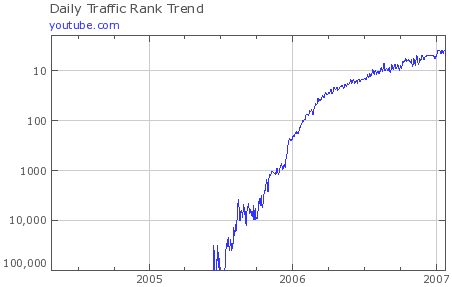
YouTube 的见解是让视频易于分享。他们免费创建了嵌入代码,鼓励用户将他们的视频添加到 MySpace 等其他网站。
这让 YouTube 的内容呈现在所有人面前。
首先,他们得到了品牌认可。人们开始熟悉他们是谁,他们做了什么。
它还通过吸走其他网站的权威,帮助创建反向链接和推荐流量。
快进几年,YouTube 现在每天处理超过 30 亿次搜索,使其成为第二大在线搜索引擎。
每个人的宠儿,Facebook,使用嵌入作为一个早期的增长黑客,以确保他们达到他们的目标,在一年内获得 2 亿新用户。
他们给用户提供了一个选择,通过创建不同的徽章让他们嵌入到其他地方,比如他们的博客、网站和论坛中,以显示他们在 Facebook 上。
这些徽章今天仍然存在。
这创造了数十亿的印象,数亿的点击量,以及每月数百万的注册量。
而且,这并不是唯一一家使用这种策略的巨头。你有没有尝试过在你的博客上分享YouTube视频?
他们让嵌入视频变得超级简单,所以很多人都会这么做。他们为你创建整个代码并突出显示,这样你只需按Cmd+C(或Ctrl+C,如果你在Windows上),然后将其粘贴到你的编辑器中。

但这不是它如此受欢迎的唯一原因。还因为YouTube视频非常容易分享。
我们还希望人们将他们的数据嵌入到Crazy Egg中–这不是一个好主意。
为什么呢?
哪家公司愿意展示他们的流量、点击、收入数字和转化率?
没有人愿意!
但是,猜猜谁想分享他们发现的最新有趣的猫咪视频?每个人都想!
小贴士:给人们一个深入挖掘你的嵌入的理由。YouTube播放器会自动播放下一个视频,或者在每个视频结束时给你一个相关视频的选择。这使得你在看完一个嵌入视频后,极有可能切换到YouTube。
当你决定是否要让你的产品可嵌入时,要确保客户有一个嵌入的理由,它很容易做到,并且你要吸引他们深入挖掘你的嵌入。
不过,还有比嵌入更强大的东西,特别是如果你做对了:集成。
您是否知道,只要让人们使用他们在Facebook、Twitter或Google上已有的账户注册您的服务,您就可以增加高达50%的注册量?
整合你的服务与另一个服务无缝对接,可以让你非常轻松地接触到数百万的潜在客户。
PayPal在大多数市场上挣扎着进入大门。很少有零售商真正将其作为一种选择。
但是,一旦他们与eBay达成协议,并将PayPal作为选项提供给Visa和万事达卡旁边,闸门就打开了。
在过去的几年里,他们的支付量甚至翻了一番。
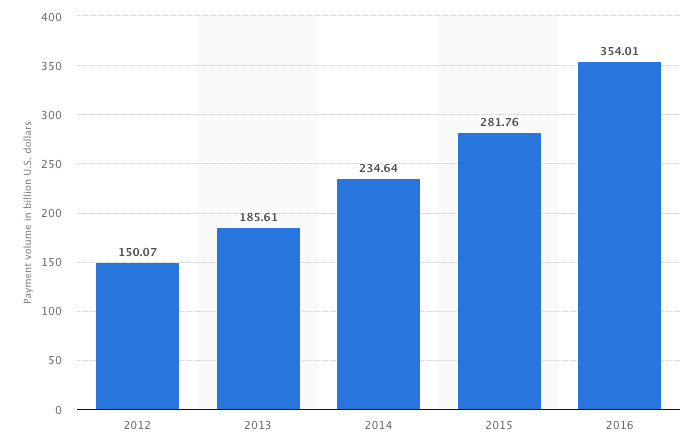
最终,eBay在2002年以15亿美元收购了PayPal。
考虑到PayPal现在的价值不仅超过了eBay,而且还超过了美国运通,这简直是偷鸡不成蚀把米。对他们来说,有一个强大的整合就够了。
但PayPal和Facebook已经是旧闻了。那最近的一些创业公司呢?
今天的整合同样有效。只不过现在,像Facebook和PayPal这样的公司才是你想要整合的对象。
Spotify就是一家这样做的公司。
下面是它的样子。
与Facebook的整合是一个非常有针对性的举措。Facebook已经是一个分享兴趣的平台,尤其是音乐(例如视频形式)。
Spotify只是让这种体验变得更好。通过在应用和Facebook流中显示你的朋友听的音乐,人们开始发现这个应用。
“汤姆在听Spotify上的Jay -Z的歌。
嗯,我想知道那是什么。让我看看 哦,这是免费的流媒体。太棒了!”
Spotify又有了新用途。顺便说一句,这正是他们得到我的方式。
与嵌入一样,确保你的整合对用户来说是有意义的,而且你的入驻过程是顺利的,这样双方都能受益。
Airbnb没有,这就是为什么他们的增长黑客最终停止了工作。幸运的是,他们在那个时候已经不需要它了。
当他们开始创建房源时,他们真的想利用Craigslist的庞大网络。
但是Craigslist并没有公开他们的API,所以Airbnb的人不得不创建一个非常困难的技术解决方案。
最终,他们实现了这一点,人们可以通过简单的点击来交叉发布他们的Airbnb列表。
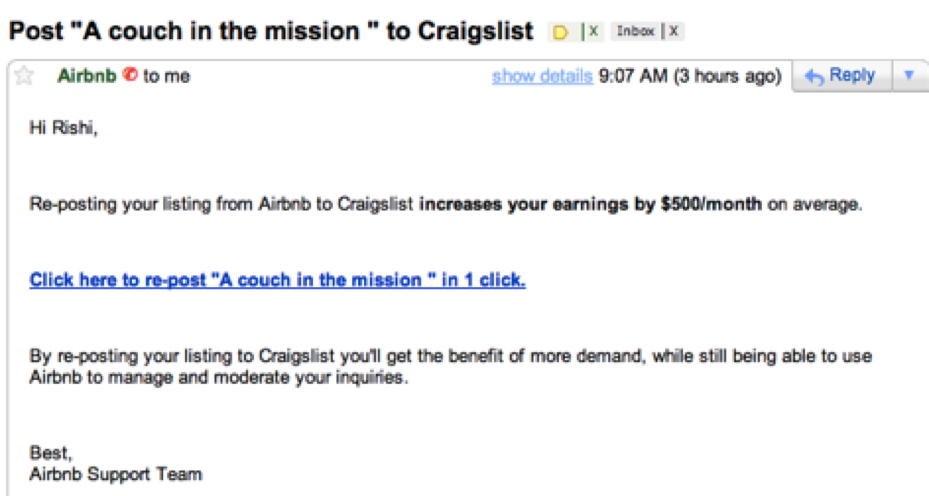
当时,每月约有5000万独立用户使用Craigslist。
这些房源后来得到了大规模的曝光,导致Airbnb的用户增长了一大段。
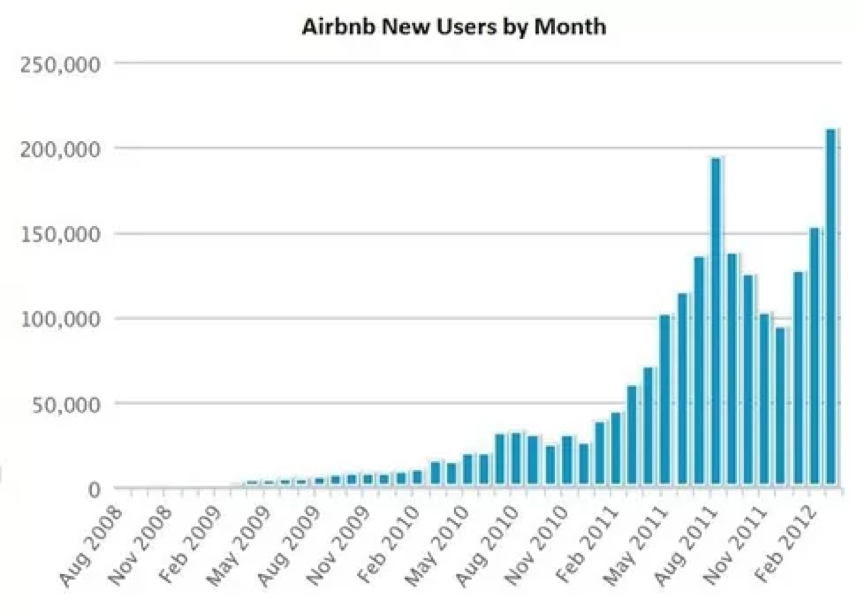
但我们只能说,这并不是一个很认可的程序,也根本没有得到Craigslist的认可。最终,他们不得不停止整合。
另一个与嵌入和集成类似的概念是 “Powered by badges”。

不过这些都需要大量的测试和优化,因为不可能马上就知道什么是有效的。
例如,对于Kissmetrics,我们发现 “Analytics by… “比 “Powered by… “好用得多。
整合、嵌入和徽章当然是你最好的赌注之一,可以让你的产品走向病毒式传播,并获得足够大的市场,成为热门产品。
尽管如此,这些例子更多的是想法,而不是 “复制这个 “计划。
你看,当越来越多的公司开始利用它们时,增长黑客通常会相当快地停止工作。
因此,与其试图复制这些例子中的每一个,不如试着进入正确的心态,看到尚未开发的机会和新的方法,让你使用类似的策略来营销你的产品。
那么,你一定要想出一些聪明的策略吗?
不,你不需要。
这里有一个使用增长黑客的初创公司的例子,它不是一家价值10亿美元的科技初创公司。
听说过 “海报沟 “吗?他们是一个让你买卖艺术品和海报的市场。
他们通过利用病毒式策略,如结构良好的赠品和联盟营销,招募 “校园创业者 “为他们获取用户,只用了一小部分成本就将他们的市场发展到100万美元。
很基本的战术,利用病毒式的基本本钱,对吧?
你不需要很花哨。你可以简单地测试已经有效的战术,看看它们的效果如何。如果你获得了很好的投资回报率,那么就可以加倍地扩大它的规模。
- 粘性增长–Facebook也有网络效应,内置病毒性。但他们追求新用户增长的方式几乎完全相反。
他们没有试图让尽可能多的人获得机会,而是反其道而行之。
Facebook一开始只针对特定的常春藤盟校。你必须在每所学校都有一个电子邮件地址才能访问。
从那里,他们慢慢扩展到其他高调的学校。这限制了供应,刺激了需求。
Facebook具有病毒性,随着越来越多的朋友加入,每个用户的价值都会增加。
然而,这个平台的粘性非常高。几乎没有任何其他平台可以与之相比。
平均每个人每天在Facebook上花费大约一个小时的时间。这几乎和人们白天吃饭的时间一样多。
而且这些趋势数字还在不断增长!
Facebook很清楚他们的用户喜欢什么,不喜欢什么。然后,他们像木偶大师一样操纵这些东西,让人们每天继续多次登录。
这意味着他们已经征服了产品粘性的神奇公式。
高留存率+低流失率+网络效应。
Kissmetrics前增长总监Lars Lofgren展示了如果你任其发展,流失率往往会(也会)开始侵蚀新客户的获取。
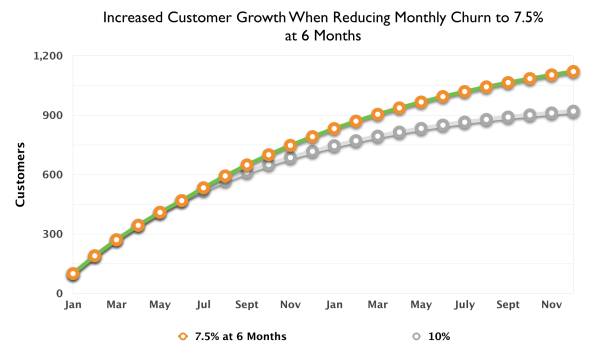
而且他还引用了Eric Ries的一个简单的经验法则,用于粘性产品。
管辖粘性增长引擎的规则非常简单: 如果新客户的获取率超过了流失率,产品就会增长。
David Skok在他关于SaaS指标的文章中写下了你可以称之为Churn Bible的东西。在其中,他引用了NetSuite的Ron Gill的话,他基本上说,流失率就像你能看到的年率或回报率的天花板。
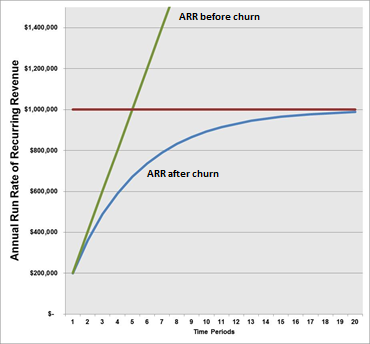
换句话说,你只能在你的流失率低的情况下成长。
负流失也可以改变游戏规则。这时,从现有客户那里增加收入的收益超过了老客户离开所损失的收入。
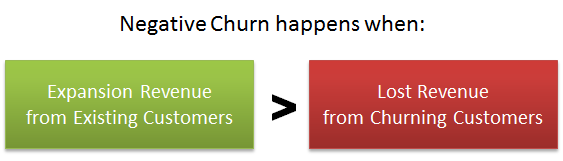
大卫-斯科克概述了两种增加的方法。
第一个是将价格与产品使用量挂钩。这样,客户使用你的产品越多,他们支付的价格就越高。例如,根据他们发送电子邮件的数量来收费。
另一个选择是向上销售或交叉销售更多/更大版本的产品。这在B2B领域特别有帮助,你可以添加一个大的、可定制的 “企业 “产品。
诚然,这是个有点深奥的宅男话题。
但坚持产品是绝对必要的。
流失率可以(也将)决定你的产品最终的成功程度。
- 付费增长–病毒性、粘性业务在软件中很常见。然而,在它之外,它们就不那么常见了。
问题是,许多其他类型的公司并没有从在线增长中获益那么多。
像Nespresso咖啡机这样的硬件公司,不能那么容易地 “病毒式 “传播,也不能通过简单地创造一个有粘性的产品来实现增长。
这些公司是如何成长的呢?他们利用商业广告。
Groupon在短短几年内通过付费增长上市时,也采取了类似的策略。
他们销售的是硬商品和服务。
他们的诀窍是在任何竞争对手跟上之前尽可能快地成长,这样他们就可以达到规模,上市,并主导优惠券领域。
你可以说所有你想要的关于他们的股票价格或性能。
但你无法反驳的是他们的增长策略。
他们的规模在一年内增长了228%。
怎么做到的?
就在上市之前,他们必须向美国证券交易委员会披露财务数据。
而其中最让人眼前一亮的一项是,他们在一个季度内花了1.79亿美元获取了3300万新用户!

“网络营销 “这一项是目前最大的费用调整。
所以他们是直接花钱获取新用户。
他们的商业模式表明,在广告上花钱是一种积极的投资。他们能够在每个注册用户上赚取一定的利润。
增长的数学很简单。花尽可能多的钱!
你有客户的终身价值(LTV)在方程的一边。这是每个客户在一段时间内的平均价值。
因此,如果有人每月付给你100美元,持续两年,那就是2400美元的LTV。
你可以也应该尽力提高这个数字。下面基于留存的策略可以帮助你。
但除此之外,你要将这个数字与获客成本(CAC)进行比较。
把获取一个客户所需的所有费用加起来。你有可能拥有设备、销售人员、营销人员、广告活动等。
因此,你在市场和销售上的花费几乎总是比你想象的要高。
中间的某个地方是你的投资回收期。这是你收回这些初始成本所需的时间。
而你可以将这一点之后的所有东西回馈给管理费用或利润。
亚马逊Prime会员每年的消费超过1300美元。这是非Prime客户消费的两倍。每月总计近1亿美元。
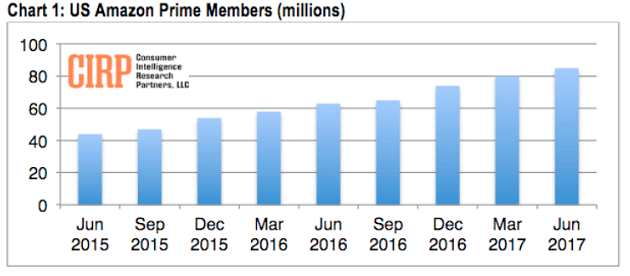
额外的利润率使他们能够重新投资于未来的增长。
例如,亚马逊出了名的产品销售利润率较低。
但最近,他们已经开始创造、销售和分销自己的产品。
而且最好的是,他们只是简单地看一个类别中最畅销的产品。所以他们已经知道什么是最有效的。
亚马逊前员工Rachel Greer透露了亚马逊是如何利用他们新的自有品牌来提高每单位销售利润的。
亚马逊既能追踪人们购买的商品,也能追踪他们搜索到的和找不到的商品,这让这家电子零售商在小卖家面前拥有巨大的优势。
他们正在研究哪些商品化的产品已经表现良好,然后简单地削弱竞争。
付费增长从一些基本的东西开始,比如广告或公关。
但正如你所看到的,它还包括在增加利润的同时降低成本,以进一步利用权力地位。
引起更多的关注和兴趣永远是第一步。然而,如果不能让这些关注度持续下去,你将永远面临一场艰苦的战斗。
以下是如何激活新的网站访问量和应用安装者,让他们长期留在这里。
步骤 4:激活
你想尽快提高转化率吗?
其实很简单。
你所要做的就是消除你的选择页面上的一些表格字段。
我只需从注册页面中删除一个表格字段,就能将我的转化率提高26%。
但是,等等。它不可能这么简单,对吗?
不幸的是,它不是。
你只是在这个免费的步骤上让选择加入变得更容易了。免费转换并不能支付账单。只有付费客户才会这样做。
这里有一个几年前的完美例子,证明了这一点。
在人们注册时要求他们提供信用卡,会增加很多摩擦。他们还不确定自己是否想要或需要你的产品。
去掉这个要求,就容易多了。
所以很容易猜到这对转化率的影响。
这是Totango的一项研究发现的。
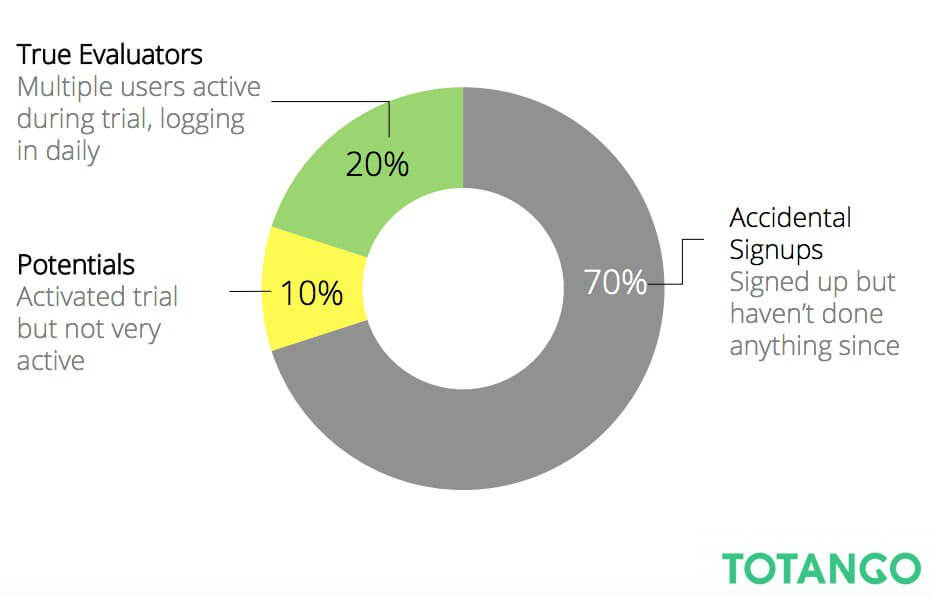
- 他们发现,不要求信用卡带来了更高的转化率(约10%)。
- 要求提供信用卡带来较低的转换率(约2%)。
你自己的情况是独一无二的。重复这项研究可能会给你不同的结果。
不过,重点还是在于。
如果更多的人只是要离开,那么让更多的人转化是没有用的。这不是一个成功的激活。
相反,你希望合格的人留在这里。注册或选择加入是一个好的开始。但它们并不能给你提供全貌。
在注册后叠加每次浏览的页面可能会给你提供你需要的背景。
Fraser Deans强调了成功收购的三个不同阶段。
- 预注册。这包括人们在选择加入之前所经历的所有 “东西”。
- 首次用户体验。这些是指导性的入职步骤,帮助人们看到你的产品的价值。
- 注册后。这是所有之后的事情,以确保他们不会有买方的后悔。
第一阶段概述了别人到达你的注册页面的所有步骤。
例如,也许他们在谷歌上搜索了一个痛点,找到了一篇博客文章,然后点击了那个页面。
也许他们先看到了一个广告,引导他们进入了一个登陆页面。
也可能他们直接输入了你的品牌名称。
这里的诀窍是优化用户流,加快每一个人的速度。
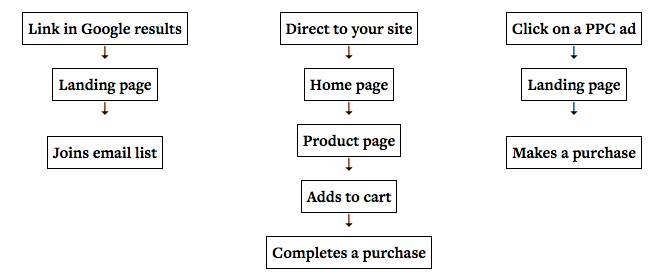
比如,我的很多网站都会在前面和中间设置一个工具选择功能。
访问Crazy Egg主页,你会看到的是一个URL栏,可以即时获得热图。
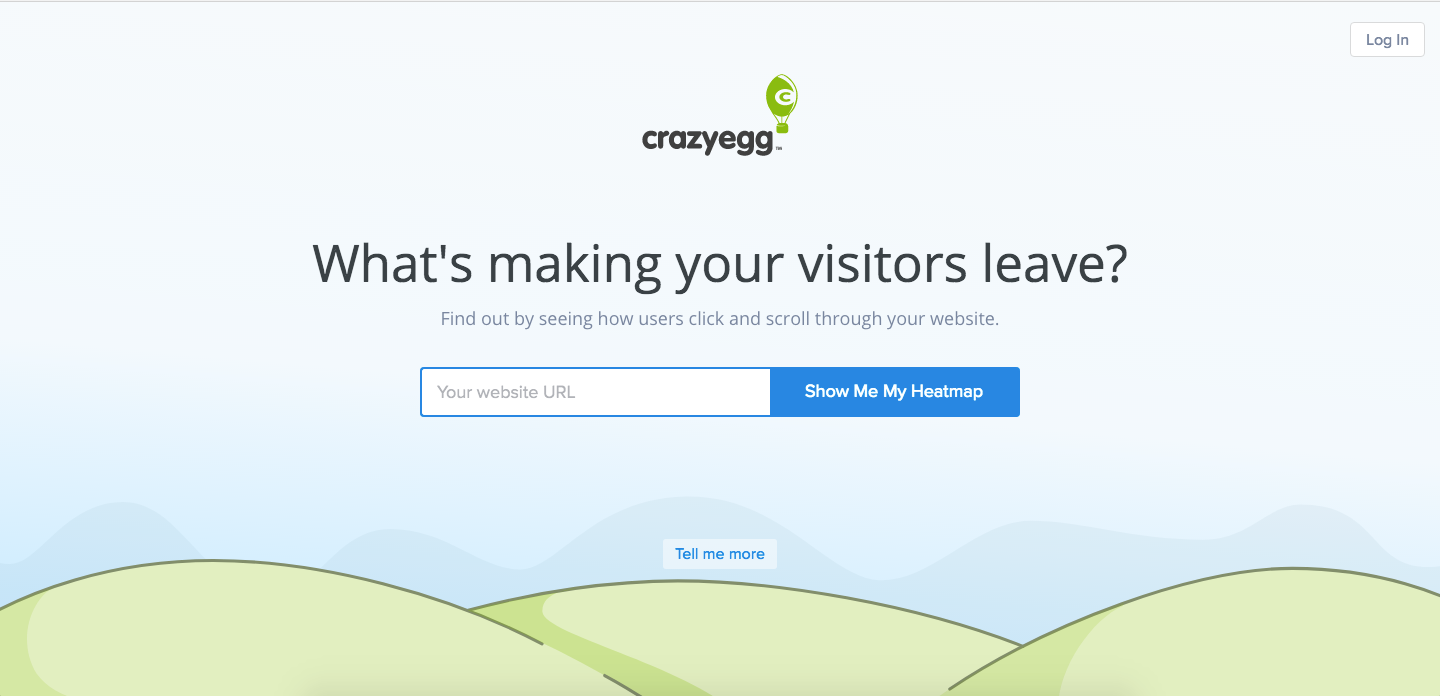
我们为什么要这么做?
我们在 “塑造 “用户流。有人可以在一篇博客文章中读到关于常见网站错误的内容。
然后,一旦他们开始浏览网站以获得更多的信息,我们可以向他们展示如何修复他们的网站。
这是令人难以置信的强大。它免费给别人带来直接的价值。
这也是我见过的最好的方法之一,让人们立即了解你的产品如何使他们受益。
当他们看到热图的那一刻,他们就会产生 “哈哈 “的感觉。
因此,从那里开始,它是一个简单的销售。
不过,让别人转化只是战役的一半。
下一步是确保发生 “快乐的第一次体验”。
这是入职阶段,在这个阶段,你可以使用教程来帮助人们学习如何从你的产品中获得最大的好处。
Claire Suellent概述了三种不同的方法,包括:
- 自助服务
- 小组演示
- 一对一通话
服务和关注程度也主要取决于产品类型。
例如,像Canva这样的简单产品是相当直接的。
通过拖拽一个小方框来裁剪照片,非常直观。
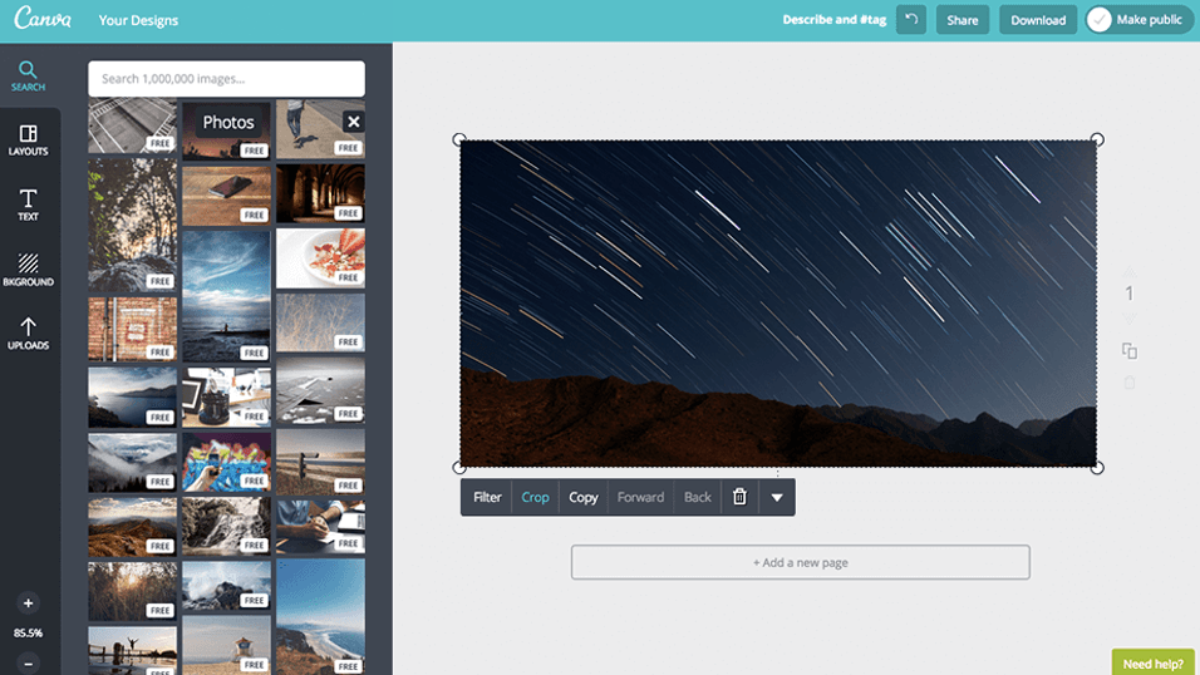
他们可能有能力使用自助服务教程,使用callout和工具提示来告诉用户下一步该点击哪里。
产品越复杂,你最初需要做的手工操作就越多。
问题不在于人们理解你产品的功能。这些很容易看到。
问题是让人们了解如何从这些东西中获益。而这往往需要一段时间来沉淀。
像HubSpot和Infusionsoft这样真正复杂的产品甚至需要你做正式的培训,然后他们才会让你松开产品。
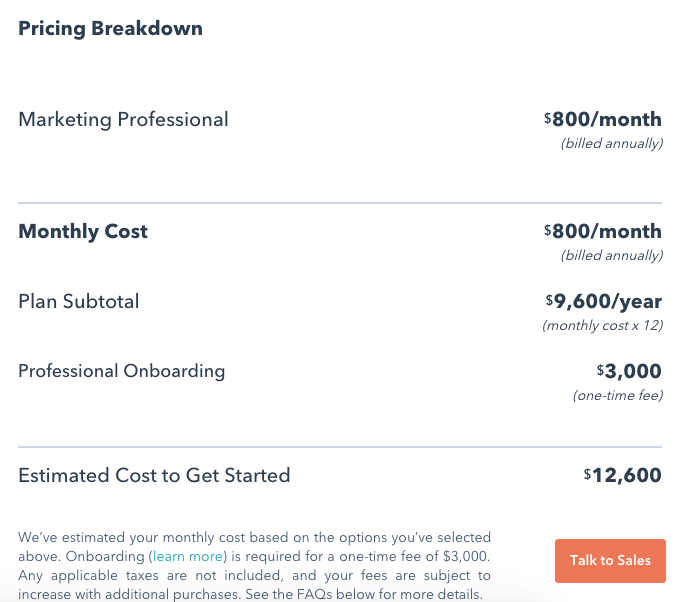
很显然,对于大多数产品来说,要求一次性收取3000元的上岗费是矫枉过正。
但它的作用是将注册的人数缩小到只有合格的人。
HubSpot愿意打赌,当你真的经历了这个过程,你将能够更有效地使用他们的产品。
而结果是,你会坚持做一个付费客户的时间更长。
把你的入职序列看作是自己的漏斗,可以帮助你发现问题所在。
例如,沿着宾果卡创造者的每个步骤,看看下面的转换。
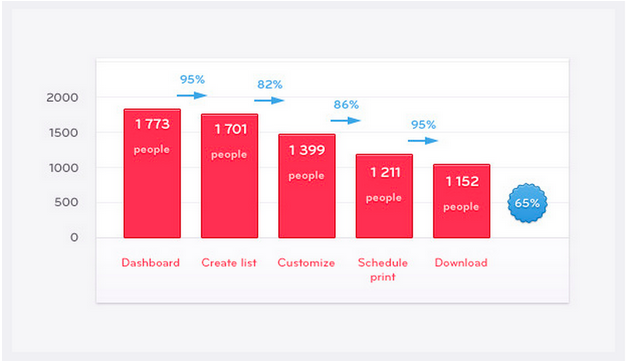
从签到仪表板到创建列表的人数看起来不错!
但下一步(从创建列表到定制列表)就没有那么好了。
这让你看到了转化路障藏在哪里,一览无余。从一个功能到另一个功能的过渡对你来说可能看起来很简单。
然而,客户数据却描绘了另一幅图景。
LinkedIn通过在零到100的范围内显示你的个人资料有多 “完整”,这也是这种策略的另一种变化。
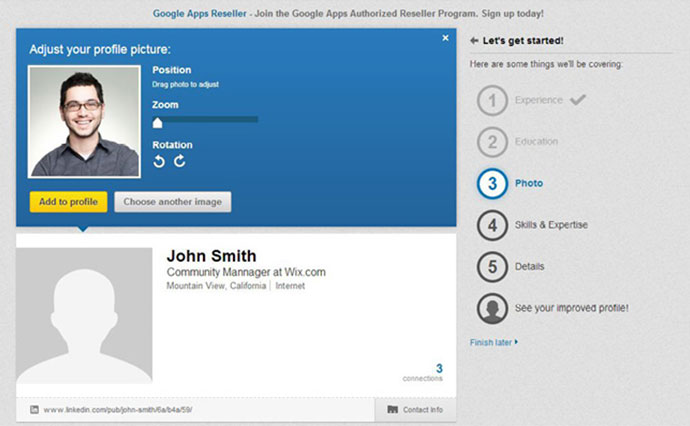
和以往一样,只有测试才能看出什么是有效的。这就是为什么增长黑客的思维方式对成功至关重要。
你需要假设潜在的解决方案,测试,衡量影响,并继续迭代,直到你找到答案。
例如,Buffer的Leo Widrich告诉Chargify,他们是如何在入职过程中不强迫用户分享一些东西,从而反直觉地发现了更多的成功。
这与你的想法完全相反,因为Buffer背后的整个理念就是改善人们分享内容的方式。有的时候,在你测试不同的方法之前,你根本无法知道什么会有效。
接下来,在整个体验中调整你的信息传递。
例如,营销自动化可以帮助你定制信息。
因此,你可以看到某人是否已经使用了某个特定的功能,如果没有,就给他们发送一封完全不同的提醒邮件来推敲他们。
大多数自动化平台将允许你为你想要的行动设置事件。
然后,你可以根据用户是否采取了该行动来改变后续消息。
如果LinkedIn上有人上传了照片,但没有填写技能、专长或以前的工作经历,猜猜他们即将收到哪条消息?
像这样的滴灌邮件不仅仅是为了辅助激活。
事实上,在留存阶段,你往往可以从中获得更多的价值,让人们一次又一次地回来。
原文:Growth Hacking Made Simple: A Step-by-Step Guide
]]>


 ]]>
]]> ]]>
]]>








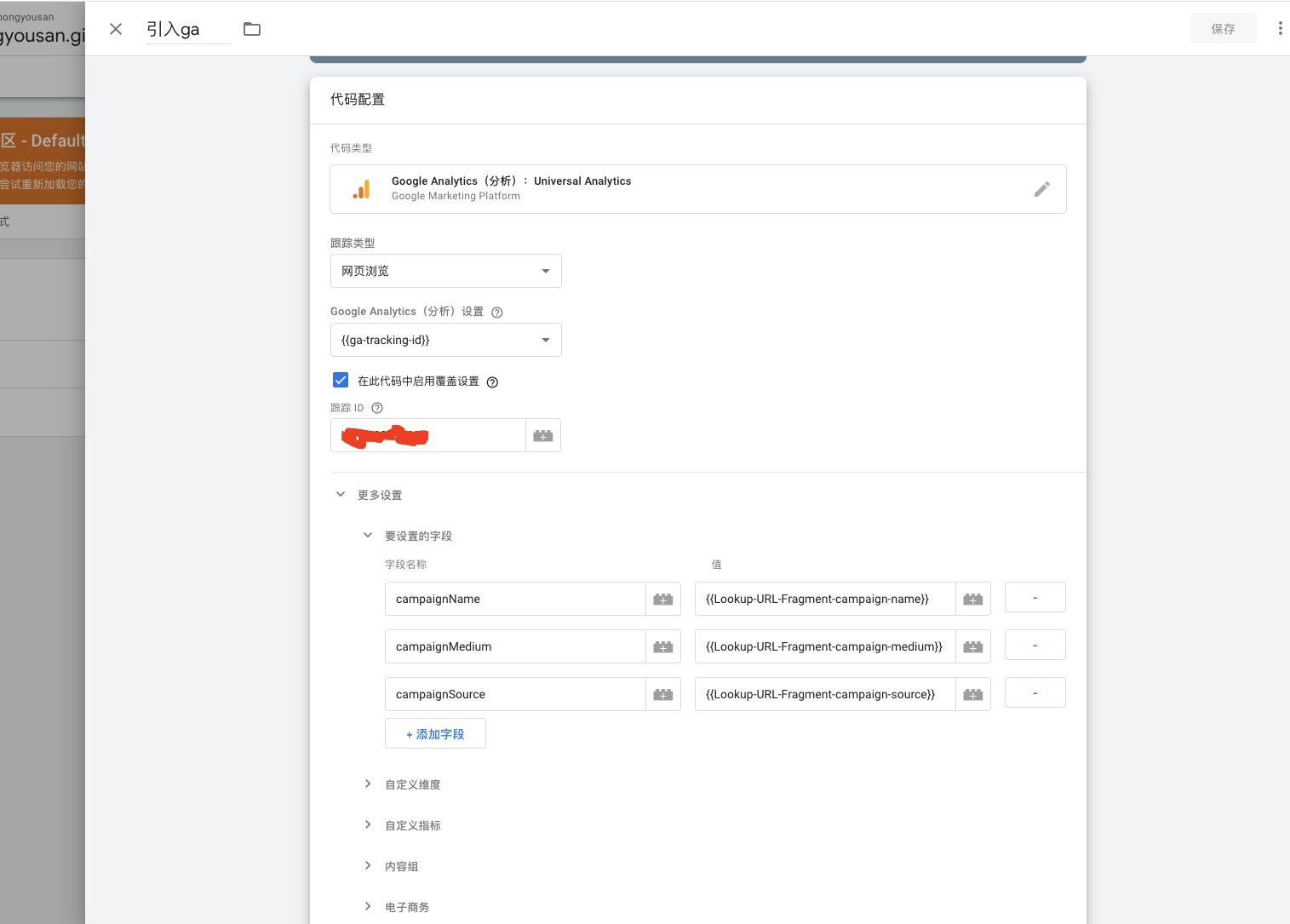
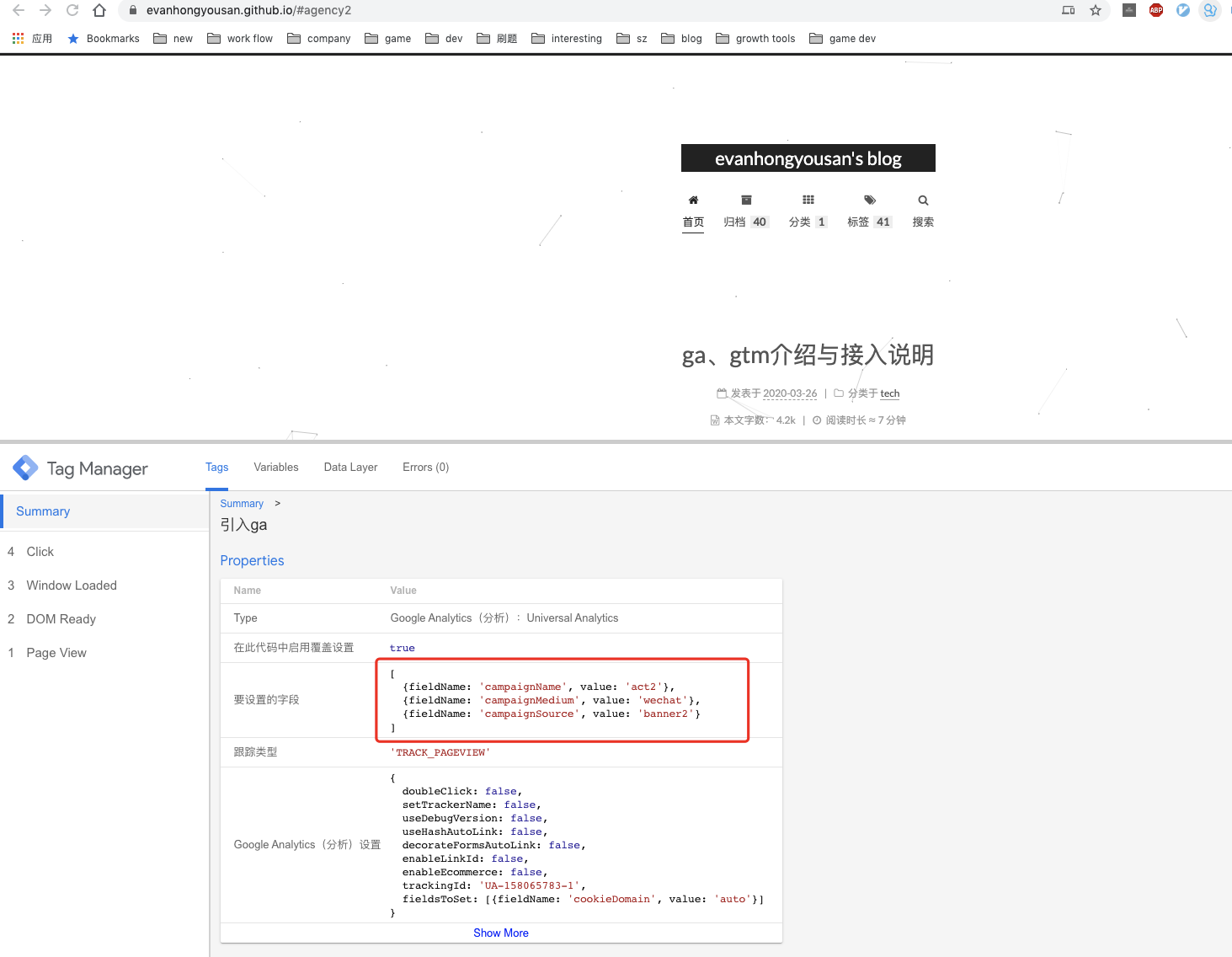
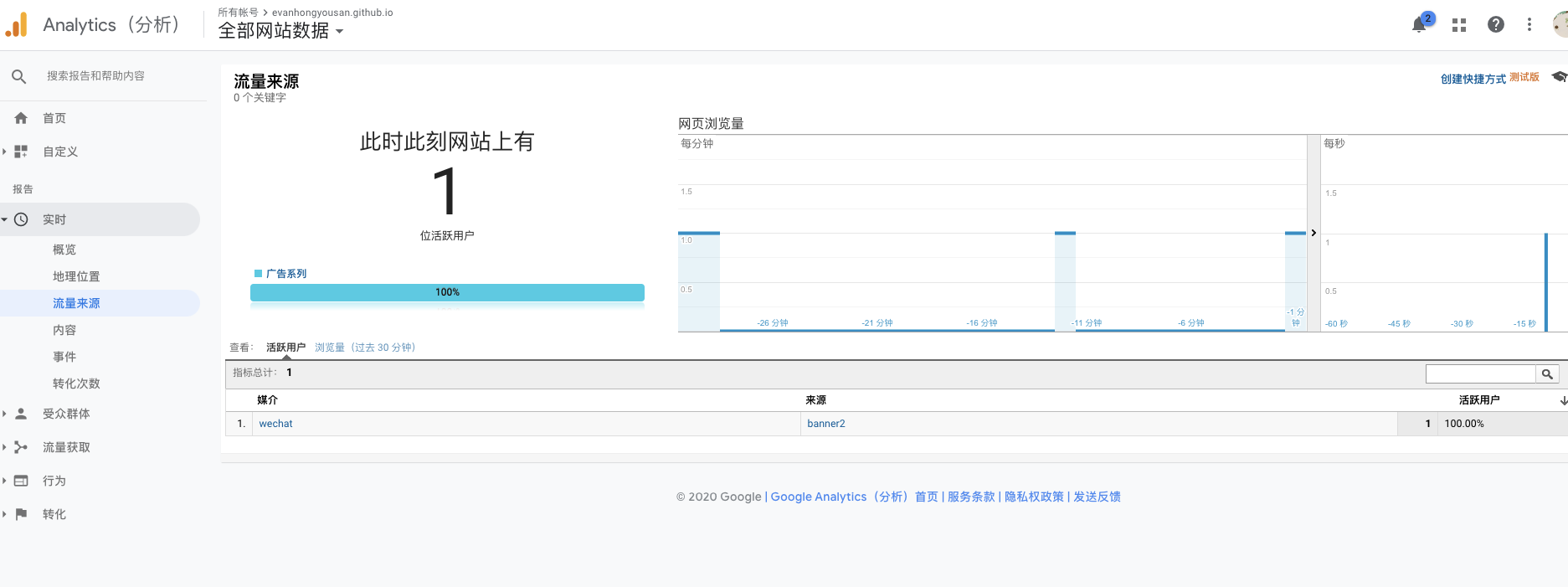
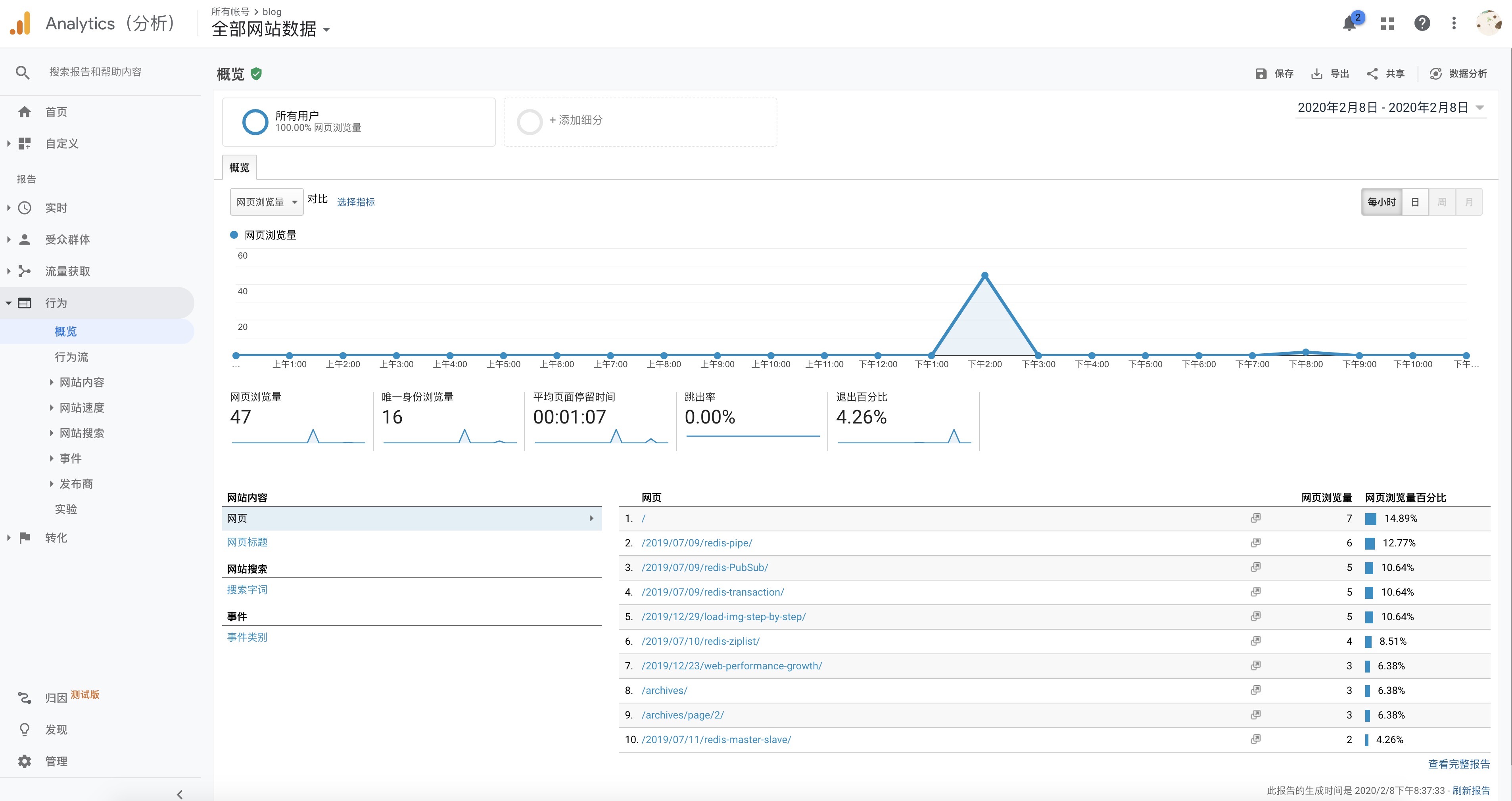

 ]]>
]]>
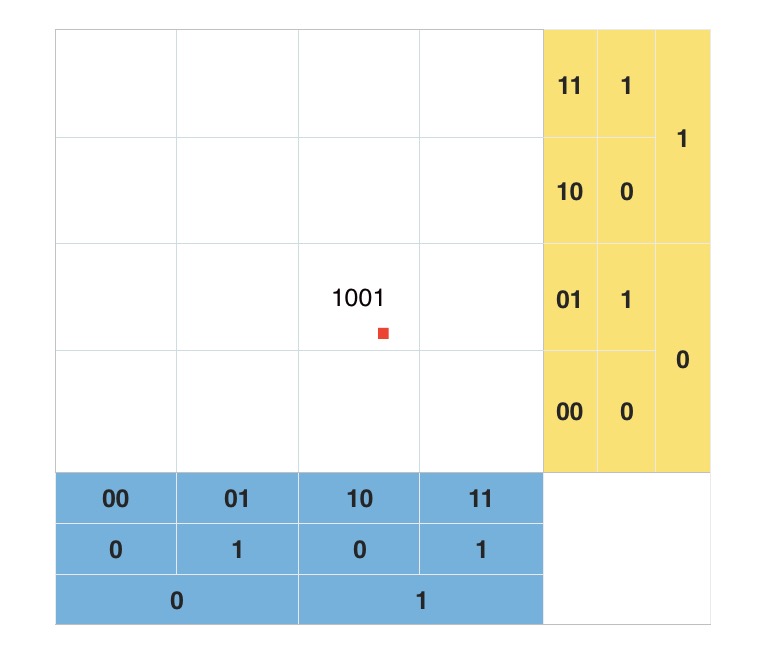
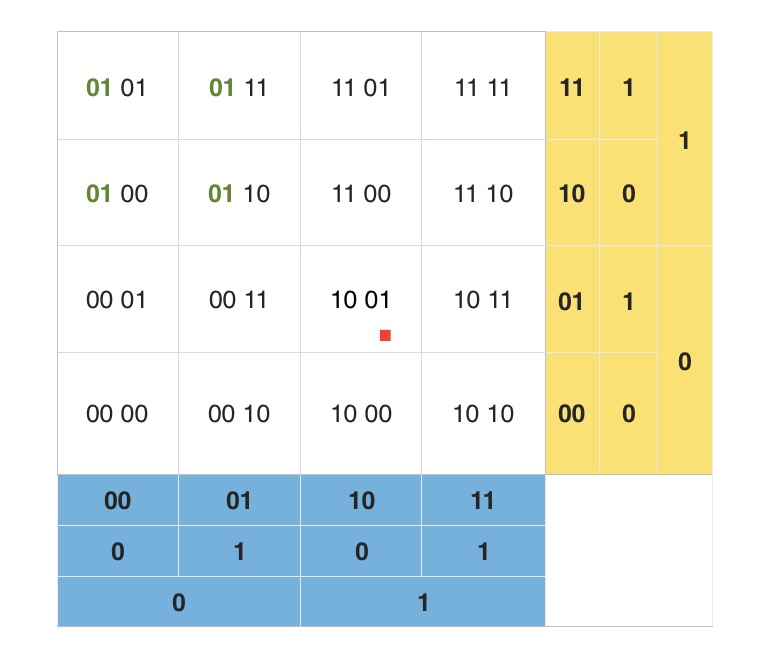

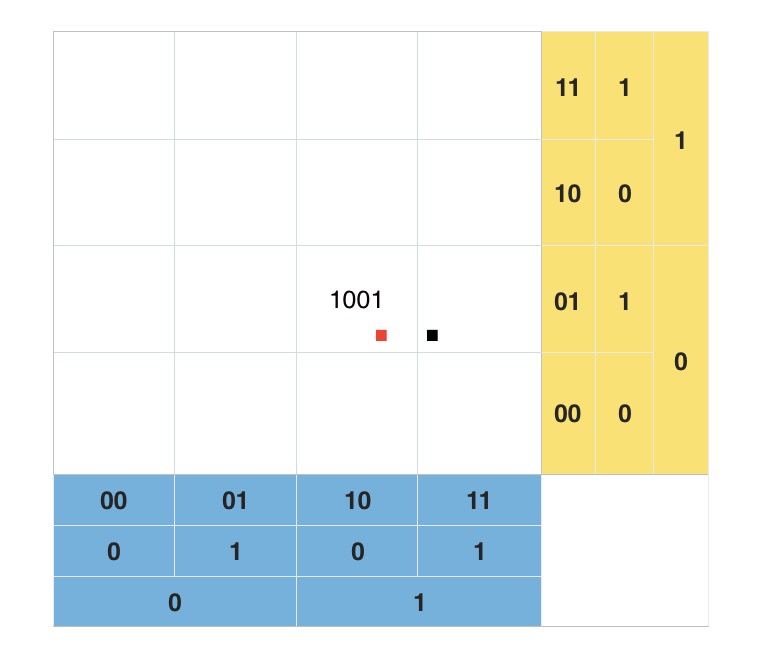
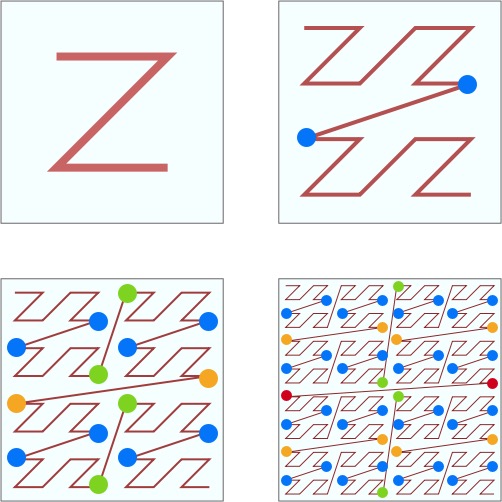 看上图中标注出来的蓝色的点点。每两个点虽然是相邻的,但是距离相隔很远。看右下角的图,两个数值邻近红色的点两者距离几乎达到了整个正方形的边长。两个数值邻近绿色的点也达到了正方形的一半的长度。
看上图中标注出来的蓝色的点点。每两个点虽然是相邻的,但是距离相隔很远。看右下角的图,两个数值邻近红色的点两者距离几乎达到了整个正方形的边长。两个数值邻近绿色的点也达到了正方形的一半的长度。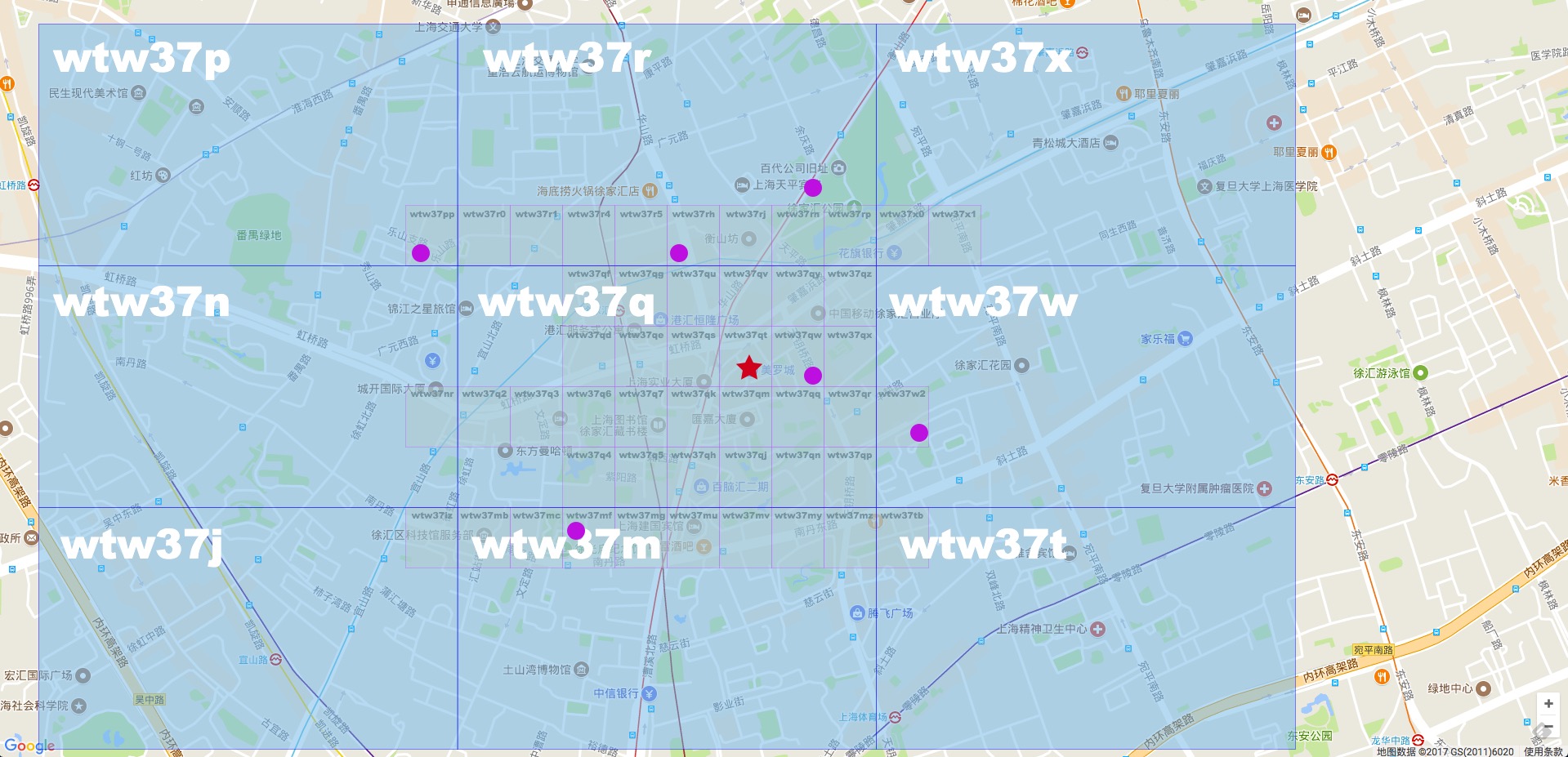
 ]]>
]]>
 ]]>
]]>


 ]]>
]]>
 ]]>
]]>